
How to steal encryption keys: Your cloud is not as secure as you may think!
People increasingly depend on cloud services for business as well as private use. This raises concerns about the security of clouds, which is usually discussed in the context of trustworthiness of the cloud provider and security vulnerability of cloud infrastructure, especially the hypervisors and cryptographic libraries they employ.
We have just demonstrated that the risks go further. Specifically, we have shown that it is possible to steal encryption keys held inside a virtual machine (that may be hosting a cloud-based service) from a different virtual machine, without exploiting any specific weakness in the hypervisor, in fact, we demonstrated the attack on multiple hypervisors (Xen as well as VMware ESXi).
Cache-based Timing Channels
The performance of modern computing platforms is critically dependent on caches, which buffer recently used memory contents to make repeat accesses faster (exploiting spatial and temporal locality of programs). Caches are functionally transparent, i.e. they don’t affect the outcome of an operation (assuming certain hardware or software safeguards), only its timing. But the exact timing of a computation can reveal information about its algorithms or even the data on which it is operating – caches can create timing side channels.
In principle, this is well understood, and cloud providers routinely take steps to prevent timing channels, by not sharing processor cores between virtual machines belonging to different clients.
Preventing L1-based cache channels
Why does this help? Any exploitation of a cache-based channel inherently depends on shared access (between the attacker and the victim) of this hardware resource. An attacker has no direct access to the victim’s data in the cache, instead cache attacks are based on the attacker’s and victim’s data competing for space in the cache. Basically, the attacker puts (parts of) the cache into a defined state, and then observes how this changes through the competition for cache space by the victim.
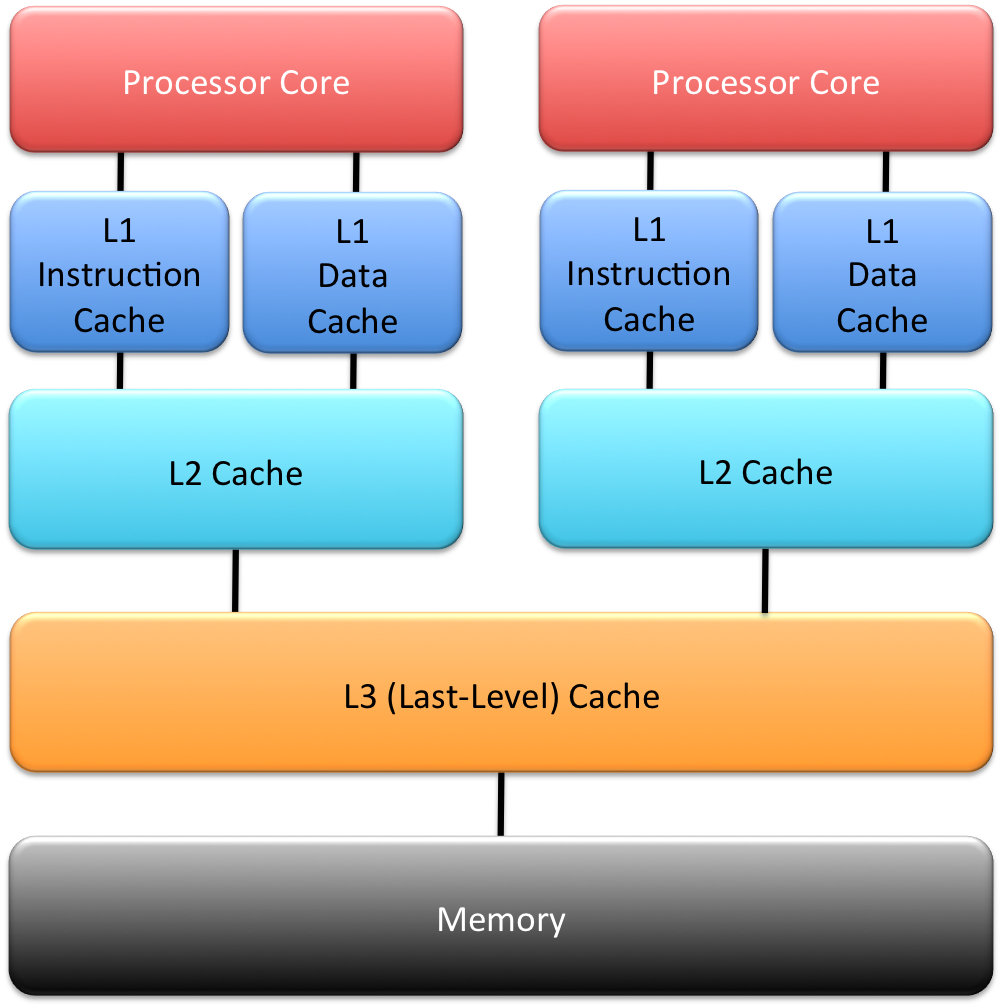
Memory architecture in a modern x86 processor.
Modern processors have a hierarchy of caches, as shown in the diagram to the right. The top-level “L1” caches (there is usually a separate L1 for data and instructions) are fastest to access by programs executing on the processor core. If a core is shared between concurrently executing virtual machines (VMs), as is done through a hardware feature called hyperthreading, the timing channel through the cache is trivial to exploit.
So, hypervisor vendors recommend disabling hyperthreading, and we can assume that any responsible cloud provider follows that advice. Hyperthreading can provide a performance boost for certain classes of applications, but typical cloud-based services probably don’t benefit much, so the cost of disabling hyperthreading tends to be low.
In principle, it is possible to exploit the L1 timing channel without hyperthreading, if the core is multiplexed (time-sliced) between different VMs. However, this is very difficult in practice, as the L1 caches are small, and normally none of the attacker’s data survives long enough in the cache to allow the attacker to learn much about the victim’s operation. Small caches imply a small signal. (Attacks against time-sliced L1 caches generally requiring the attacker to force high context-switching rates, eg by forcing high interrupt rates, something the hypervisor/operator will consider abnormal behaviour and will try their best to prevent.)
In somewhat weaker form, what I have said about L1-based attacks also applies to other caches further down in the memory hierarchy, as long as they are private to a core. On contemporary x86 processors, this includes the L2 cache. L2 attacks tend to be harder than L1 attacks for a number of reasons (despite the larger size of the L2, compared to the L1), and the same defences work.
Attacking through the last-level cache (L3)
The situation is different for the last-level cache (nowadays the L3), which, on contemporary x86 processors, is shared between multiple cores (either all cores on the processor chip, or a subset, called a cluster).
What is different is that, on the one hand, the cache is further away from the core, meaning much longer access times, which increases the difficulty of exploiting the timing channel. (Technically speaking, the longer access time reduces the sampling rate of the signal the attacker is trying to measure.) On the other hand, the fact that multiple cores access the same L3 concurrently provides an efficiency boost to the exploit (by increasing the rate at which the signal can be sampled), similar to the case of the L1 cache with hyperthreading enabled.
Still, L3-based attacks are difficult to perform, to the point that to date people generally don’t worry about them. There have been attacks demonstrated in the past, but they either depended on weaknesses (aka bugs) in a specific hypervisor (especially its scheduler) or on unrealistic configurations (such as sharing memory between VMs), which obviously break inter-VM isolation – a security-conscious cloud provider (or even a provider concerned about accounting for resources accurately) isn’t going to allow those.
It can be done!
However, these difficulties can be overcome. As we just demonstrated in a paper that will be presented at next month’s IEEE Security and Privacy (“Oakland”) conference, one of the top security venues, the L3 timing channel can be exploited without unrealistic assumptions on the host installation. Specifically:
- We demonstrated that we can steal encryption keys from a server running concurrently, in a separate VM, on the processor.
- Stealing a key can be done in less than a minute in one of our attacks!
- The attack does not require attacker and victim to share a core, they run on separate cores of the same processor.
- The attack does not exploit specific hypervisor weaknesses, in fact we demonstrated it on two very different hypervisors (Xen as well as VMware ESXi).
- The attack does not require attacker and victim to share memory, even read-only (in contrast to earlier attacks).
- We successfully attack multiple versions of encryption (which use different algorithms).
What does this mean in practice?
The implications are somewhat scary. The security of everything in clouds depends on encryption. If you steal encryption keys, you can masquerade as a service, you can steal personal or commercial secrets, people’s identity, the lot.
Our attack targeted two specific implementations of a crypto algorithm in the widely used GnuPG crypto suite, it exploits some subtle data-dependencies in those algorithms, which affect cache usage, and thus can be analysed by a sophisticated attacker to determine the (secret!) encryption keys. Ethics required that we informed the maintainers to allow them to fix the problem (we provided workarounds) before it became public. The maintainers updated their code, so an installation running up-to-date software will not be susceptible to our specific attack.
However, the problem goes deeper. The fact that we could successfully attack two different implementation of encryption means that there are likely ways to attack other encryption implementations. The reason is that it is practically very difficult to implement those algorithms without any exploitable timing variations. So, one has to assume that there are other possible attacks out there, and if that’s the case, it is virtually guaranteed that someone will find them. Eventually such a “someone” will be someone nasty, rather than ethical researchers.
Why do these things happen?
Fundamentally, we are facing a combination of two facts:
- Modern hardware contains a lot of shared resources (and the trend is increasing).
- Mainstream operating systems and hypervisors, no matter what they are called, are notoriously poor at managing, and especially isolating, resources.
Note that we did not exploit anything in the hypervisor most people would consider a bug (although I do!), they are simply bad at isolating mutually-distrusting partitions (as VMs in a cloud are). And this lack of isolation runs very deep, to the degree that it is unlikely to be fixable at realistic cost. In other words, such attacks will continue to happen.
To put it bluntly: From the security point of view, all main-stream IT platforms are broken beyond repair.
What can be done about it?
Defending legacy systems
The obvious way to prevent such an attack is never to share any resources. In the cloud scenario, this would mean not running multiple VMs on the same processor (not even on different cores of that processor).
That’s easier said than done, as it is fundamentally at odds with the whole cloud business model.
Clouds make economic sense because they lead to high resource utilisation: the capital-intensive computing infrastructure is kept busy by serving many different customers concurrently, averaging out the load imposed by individual clients. Without high utilisation, the cloud model is dead.
And that’s the exact reason why cloud providers have to share processors between VMs belonging to different customers. Modern high-end processors, as they are deployed in clouds, have dozens of cores, and the number is increasing, we’ll see 100-core processors becoming mainstream within a few years. However, most client VMs can only use a small number of cores (frequently only a single one). Hence, if as a cloud provider you don’t share the processor between VMs, you’ll leave most cores idle, your utilisation goes down to a few percent, and you’ll be broke faster than you can say “last-level-cache timing-side-channel attack”.
So, that’s a no-go. How about making the infrastructure safe?
Good luck with that! As I argued above, systems out there are pretty broken in fundamental ways. I wouldn’t hold my breath.
Taking a principled approach to security
The alternative is to build systems for security from the ground up. That’s hard, but not impossible. In fact, our seL4 microkernel is exactly that: a system designed and implemented for security from the ground up – to the point of achieving provable security. seL4 can form the base of secure operating systems, and it can be used as secure hypervisor. Some investment is needed to make it suitable as a cloud platform (mostly to provide the necessary management infrastructure), but you can’t expect to get everything for free (although seL4 itself is free!)
While seL4 has already a strong isolation story, so far this extends to functional behaviour, not yet timing. But we’re working on exactly that, and should have a first solution this year.
So, why should you believe me that it is possible to add such features to seL4, but not to mainstream hypervisors? The answer is simple: seL4 is designed from ground up for high security, and none of the mainstream systems is. And second, seL4 is tiny, about 10,000 lines of code. In contrast, main-stream OSes and hypervisors consist of millions of lines of code. This not only means they are literally full of bugs, thousands and thousands of them, but also that it is practically impossible to change them as fundamentally as would be required to making them secure in any serious sense.
In security, “small is beautiful” is a truism. And another one is that retrofitting security into a system not designed for it from the beginning doesn’t work.
Update June’16
Researchers from Wochester Polytechnic have in the meantime demonstrated our attack on a real Amazon AC2 cloud. This shows beyond doubt that the threat is real. Which, of course, doesn’t stop could providers from sticking their heads in the sand.

Hey Gernot, cool paper (we just discussed it in a reading group), but the logic leap to “we should use seL4” is astounding. Why do you think seL4 can defend against shared-cache attacks any better than a legacy hypervisor?
Hi AB,
Properly partition everything in a multi-million-SLOC hypervisor seems hopeless. Even if you partition userland, there are going to be channels through the kernel (although I can’t yet prove that they can be exploited as side channels).
With seL4, owing to its isolation-driven design, we can do this, as shown in principle on last year’s CCS paper (http://ssrg.nicta.com.au/publications/nictaabstracts/Cock_GMH_14.abstract.pml). Proper design and evaluation is in progress.