

… and seL4 and RISC-V Foundations form an alliance
In June 2020 we announced that the seL4 microkernel, the world’s first operating system (OS) kernel with a machine-checked proof of implementation correctness, has now also been verified for the RV64 architecture, making it the first formally verified OS for RISC-V. We are pleased to announce that this verification has now been extended to the executable binary, meaning that the machine code running on the processor is proved to be correct against the kernel’s specification. RISC-V is the first 64-bit architecture for which this has been achieved.
What does this mean?
The previously announced proof means that, according to the semantics of the C language in which seL4 is implemented, the kernel will always behave as specified. Among others this means that seL4 cannot be attacked with stack overflows, malformed inputs or other forms of code injection or control-flow hijacking – it is provably secure in a very strong sense. However, there is still the risk of security holes resulting from a buggy (or compromised) C compiler, or from the compiler and kernel developers interpreting the C semantics differently.
The newly completed binary verification completely removes these risks – it guarantees that properties we prove about the C code hold for the executable code, and thus that the executable kernel binary behaves as required by the kernel’s formal specification.
More than porting to a different ISA

While seL4’s implementation correctness proofs use interactive theorem proving, with hundreds of thousands of (mostly hand-written but machine-checked) lines of proof, the binary verification uses an automated tool chain (see the seL4 White Paper for details). The tool chain converts both the C code as well as the binary into an intermediate language that represents the control flow of the program. It then uses SMT solvers to prove equivalence of the two programs, one short code sequence at a time.
SMT solvers prove properties by a very efficient exploration of the state space, using state compression techniques to make the problem tractable. We had previously built the binary-verification toolchain for the 32-bit Armv7 architecture. As the state space grows exponentially with the word size, taking the step to a 64-bit architecture requires overcoming significant scalability challenges – which the ingenuity of our team around Matt Brecknell and Zoltan Kocsis could overcome in the end.
Further implications
This work represents a significant step for both the RISC-V and seL4 ecosystems. No 64-bit architecture other than RISC-V presently has an OS with such a comprehensive verification and security story. And seL4 has with RISC-V the ideal base for driving further innovation in computer system security, especially for our work on the systematic prevention of information leakage through timing channels, based on the approach we call time protection. Stay tuned for more exciting results to come!

We are now formalising the link between the two ecosystems by announcing that RISC-V International and the seL4 Foundation are joining each other as Associate Members.
Sounds great! But what does it mean?
seL4
seL4 (pronounced ess-e-ell-four) is arguably the world’s most secure operating system (OS) kernel.
The OS kernel is the lowest level of software running on a computer system. It is the code that executes in privileged mode (S-mode in RISC-V; M-mode is reserved for microcode/firmware). The kernel is ultimately responsible for the security of a computer system.
seL4 is a microkernel. The idea of a microkernel is to minimise the trusted computing base – the part of the system for which there is no Plan B if it fails. The Linux and Windows kernels consist of tens of millions of lines of code, and contain literally thousands (more likely tens of thousands) of bugs – a huge attack surface. A well-designed microkernel, such as seL4, has about ten thousand lines – inherently more trustworthy.
What sets seL4 aside from all other OS kernels, including other microkernels, is its verification story. It was the world’s first OS kernel with a machine-checked, mathematical proof of the functional correctness of its C implementation (winning us a Hall of Fame Award as a result). This means that it is proved to be bug-free relative to a specification formulated in a mathematical logic. And by now it has proofs about further security properties (which show that the specification has the right properties) and functional correctness extending down to the binary code. And it has the most advanced support for hard real-time systems. And it is the world’s fastest microkernel. It’s best in class by any definition.
We originally verified seL4 for 32-bit Arm processors. We then extended that to 64-bit x86 processors. And now to RISC-V RV64 processors. Which now covers all the important ISAs.
seL4 on RISC-V
But the combination of seL4 and RISC-V is special.
RISC-V is an open instruction-set architecture (ISA). seL4 is an open-source OS microkernel. It’s a match made in heaven. Especially in terms of security.
When we verify seL4, we have to assume that the hardware operates correctly (i.e. as specified). That assumes that there is an unambiguous specification in the first place, which is not the case for all hardware. But even where there is such a specification, and it is formal (meaning written in a mathematical formalism that supports mathematical reasoning about its properties), how do we know that it actually captures the behaviour of the hardware? Reality is we can be pretty sure that it does not. Hardware is no different from software in that both have bugs.
But having an open ISA has advantages that go beyond being free of royalties. One is that it allows having open-source hardware implementations. An example of this is the CVA6 (formerly Ariane) core developed at ETH Zurich. With an open-source implementation, you see what you get, and can check for yourself whether it has security-critical bugs. This is what German company HENSOLDT Cyber GmbH did: they produced a chip, based on Ariane, with a strong supply-chain security story. And, to complement this with a secure OS, funded the verification of seL4 on RISC-V. [Disclaimer: I have an interest in HENSOLDT Cyber.]
The most exciting aspect of an open ISA with open-source hardware implementations is the prospect of verifying the implementations. This sounds like a big ask that will be hard to realise. But the same was said about a verified OS kernel – until we did it. I know there are multiple groups working towards this goal, and sooner or later one of them will succeed. This will be a revolutionary step towards achieving real security, and I bet it’s only a few years away!
Hardware-software co-design for security
Open-source hardware with a verified, open-source OS is a great thing for security, but there is more.
The combination of open ISA, open-source OS and open-source hardware enables innovation at the hardware-software interface that was previously reserved for hardware manufacturers (and thus happened at a snail’s pace). This is really important for security.
We are all aware of Spectre attacks, which use side effects of speculative execution to steal secrets. What is less understood is that speculative execution on its own is not enough. Spectre needs a covert timing channel to get the information out. Without the covert timing channel there is no Spectre attack.
Preventing these covert timing channels happens to be something we’ve been working on for a few years. We developed OS mechanisms for preventing them, but only to realise that they don’t quite work. Digging deeper, we found that this is because the hardware doesn’t give us the right mechanisms. In other words, most existing hardware is broken in terms of security! And the underlying cause is the ISA, which is our hardware-software contract. The ISA specifies functionality of the hardware, but intentionally abstracts away anything to do with time. But timing can be used to leak information, and the ISA does not provide the means for stopping this. As such, the ISA is insufficient for ensuring security, and must be improved.
This would normally be hopeless endeavour: trying to convince hardware manufacturers to agree to a new contract that imposes additional restriction on what they can do. (Trust me, I’ve tried!) Or even provide the OS with an extra instruction it can use to defeat covert channels – as long as the house is not on fire, they are unlikely to listen. And the Spectre fire is apparently not burning hot enough yet.
Open hardware changes this. It enables us to innovate without waiting for manufacturers. It enables us to control both sides of the fence. It enables true co-design, for the benefit of security.
Partnering with the creators of Ariane at ETH Zurich, we did exactly that: We explored how we can amend the hardware-software contract just a bit to give the OS the right means to defeat covert channels. And we could demonstrate that it takes very little to be highly effective.
The relevant working groups in the RISC-V Foundation are discussing these mechanisms right now. Stay tuned for RISC-V setting the benchmark in processor security, complementing the world’s most secure OS kernel – seL4.
What to know more?
The seL4 web site explains seL4, and has a whitepaper, written for non-experts, that explains seL4 and its verification story in detail.
[Note: This blog was originally written for the RISC-V blog site.]
Update 2020-07-30: fixed CVA6 link

We have created the seL4 Foundation!
But what is the seL4 Foundation, and why did we create it?
In a nutshell, these are the reasons (I’ll expand on them below):
- Provide for the longevity of seL4 beyond support from any specific organisation
- grow and integrate the seL4 ecosystem
- protect and promote the seL4 brand
- provide a platform for funding on-going engineering as well as sharing the cost of big-ticket verification items.
Why seL4 Foundation
Ensure longevity of seL4
seL4 is a game-changer for safety- or security-critical systems. Being an OS microkernel, seL4 is at the bottom of any software stack. To use it properly and to achieve the strong security properties enabled by seL4, the system must be engineered for seL4. This may require a long-term commitment, requiring significant resources. You therefore want to make sure seL4 stays around, is well-supported, and continues to provide those guarantees.
The viability of seL4 is strongly tied to its developers, the Trustworthy Systems (TS) team, and especially the technical leadership of TS. This in itself is not a problem, because everyone knows how committed we are to the success of seL4. And because there are four technical leaders for the kernel (Kevin, Gerwin, June and myself), we have a degree of redundancy (although we do work best as a team!)
We believe that as an independent, nonprofit organisation, the seL4 Foundation can make the seL4 story even stronger, and an even better choice for developers who build trustworthy systems. This is especially true if you consider a time-scale of decades, which is necessary for many of the early adopters of seL4 in the infrastructure, medical, and defence domains. By setting up an organisational framework that is supported by (and accountable to) adopters (subject to providing financial support, of course) we can plan for the future. Our Board of Directors will represent the voices of significant adopters, which will help keep the technical leadership aware and responsive to the needs of adopters.
Grow and integrate the seL4 ecosystem
Right now, the biggest barrier to uptake of seL4 is probably the lack of system components and tools. This includes board-support packages (BSPs), device drivers, file systems, networks stacks, high-level programming environments (something at the abstraction level of POSIX, but preferably based on a more suitable model), and configuration and development tools. Plus debuggers, IDEs etc.
Without some supporting organisation, many of those missing bits will have to be (re)built by every adopter. This would a huge waste of effort better spent developing new trustworthy systems. Furthermore, I believe that there are plenty of people out there who would be happy to contribute if there were more guidance, active community engagement, and a clear shared direction forward, so that the contributor can be confident their input will make a difference for the long term.
We think that the way to address this is having a forum where the community, including developers, adopters, and researchers can meet and engage. The seL4 Foundation as an open and neutral entity, where the broader community is represented, and strategy is discussed openly, seems the right way to do this.
Protect and promote the seL4 brand
seL4 has become a recognised brand that is strongly associated with its unique properties – the world’s fastest and most advanced microkernel, with a powerful assurance story. Even ten years after we concluded the original proofs, there is still no other general-purpose, non-toy OS kernel with a proof of implementation correctness. And on top of all this, seL4 is open source.
These properties drive the adoption of seL4, providing a competitive advantage to the developers of seL4-based products. But, of course, this creates expectations: a system based on “verified seL4” is expected to be more trustworthy than others. This trust could be undermined by adopters who modify the kernel. Let me explain why.
Mathematical proof provides the strongest assurance possible. But the guarantees it provides need to be thoroughly understood, in order to avoid being misleading the people who rely on them. Even mathematical proof can never cover everything: It always relies on a specific scope (eg. the assumption that the hardware behaves correctly). If these conditions are misunderstood, you might overestimate the guarantees that you get. In particular, the proofs are for very specific versions of the kernel and against a very specific specification. A seemingly trivial code change may invalidate the assumptions and thus void any assurance.
Adopters need clarity on this. Also, a company that sees a competitive advantage in having a verified system does not want this advantage undermined by others taking shortcuts and making unsubstantiated verification claims.
The Foundation will help by officially “blessing” the status of verified versions and precisely identifying the conditions under which they hold. This should help provide clear provenance, so seL4 adopters will be able to assign liability resulting from someone hacking an unverified version to where it belongs: to those providing such unblessed code.
In addition, it should be more visible what changes will affect proofs. That can informally happen with documentation, but a better solution will be a framework where adopters can run the proofs themselves, on the code base they are deploying, to confirm that the proofs still hold. Such a framework will, of course, also help contributors to identify whether adopting their changes will be straightforward (if they do not invalidate the proofs).
All this must go hand-in-hand with the promotion of seL4 and its benefits. The best way to achieve this is through a broad membership base. If you’re reading this, you clearly have some interest in seL4 – please join!
Fund on-going engineering and big-ticket items
seL4 is the result of big investments. Firstly by the Australian tax payers, who (through NICTA) funded its creation, and (through NICTA and then CSIRO’s Data61) continued supporting it. Over the past 6 years, US taxpayers (mostly through DARPA, but also other parts of the DoD as well as DHS) invested a lot in completing and extending the verification story, as well as deploying on real-world systems. And most recently, HENSOLDT Cyber funded verification of the RISC-V port of the kernel. [Disclosure: I have an interest in HENSOLDT Cyber.]
These are awesome expressions of confidence in seL4 and the team behind it, and we are immensely grateful for this support. Yet, we need more.
On the one hand we need a revenue stream to fund on-going support of the community, maintenance of existing versions, improvements of the infrastructure (in particular the automation of the seL4 verification framework). We need support for what we call strategic engineering – evolving the kernel and, importantly, developing the ecosystem. While we hope that much of the latter will eventually be done by the community, we will for now have to keep showing the way, by providing reference designs and sample components. This is obviously needed to make seL4 an attractive platform for commercial systems.
On the other hand, we have a number of big-ticket items that are crucial to our aim of making seL4 the Linux of the embedded world. The biggest of these are:
- Verification of the 64-bit Arm kernel
- Verification of the multicore kernel
There are plenty of companies keen to see both of these (and a few others) done, and several of them are willing to put money on the table to make it happen. However, the investment required for these two is above the pain limit of what most companies can justify for an open-source project, where they cannot walk away with a bunch of proprietary IP. But most can see the value of enabling it as an open-source platform.
So this is the third major goal of the Foundation: Provide on-going base funding, and bring these interested parties together and divide the required investment in a way that keeps individual contributions below the pain limit.
Together we can do it – we can change the world of critical systems, to achieve real security!
What will the seL4 Foundation do?
Obviously, the core function of the Foundation is to address the above four points, which were the rationale for setting it up in the first place. But how will this work in practice?
Community engagement
This is really the central mission: Engage and grow the community of seL4 developers and adopters, and direct and standardise the evolution of seL4 and its ecosystem.
There are several aspects to this. On the one hand there is the seL4 kernel and its proofs, on the other hand there is all the stuff around it that is essential to using it. And everyone who has had a serious look at seL4 will appreciate that the 10kLOC kernel is just the foundation – you need so much more to build a system on it!
As mentioned above, this is really the biggest barrier to uptake at the moment. There is not a lot of seL4-based userland that is ready to use, and there is very limited support through tools and development environments. Reality is that anyone who wants to deploy seL4 in a real-world system ends up developing much of this themselves.
This is obviously a waste! It will be to everyone’s benefit if at least the core components and tools are shared. Things like device drivers, network stacks, or core system services contain no IP of value but bear a significant cost. We need to reduce the cost by sharing those artefacts. There are two aspects here: Those who are developing such artefacts should share them with the community, and members of the community should adopt and maintain them.
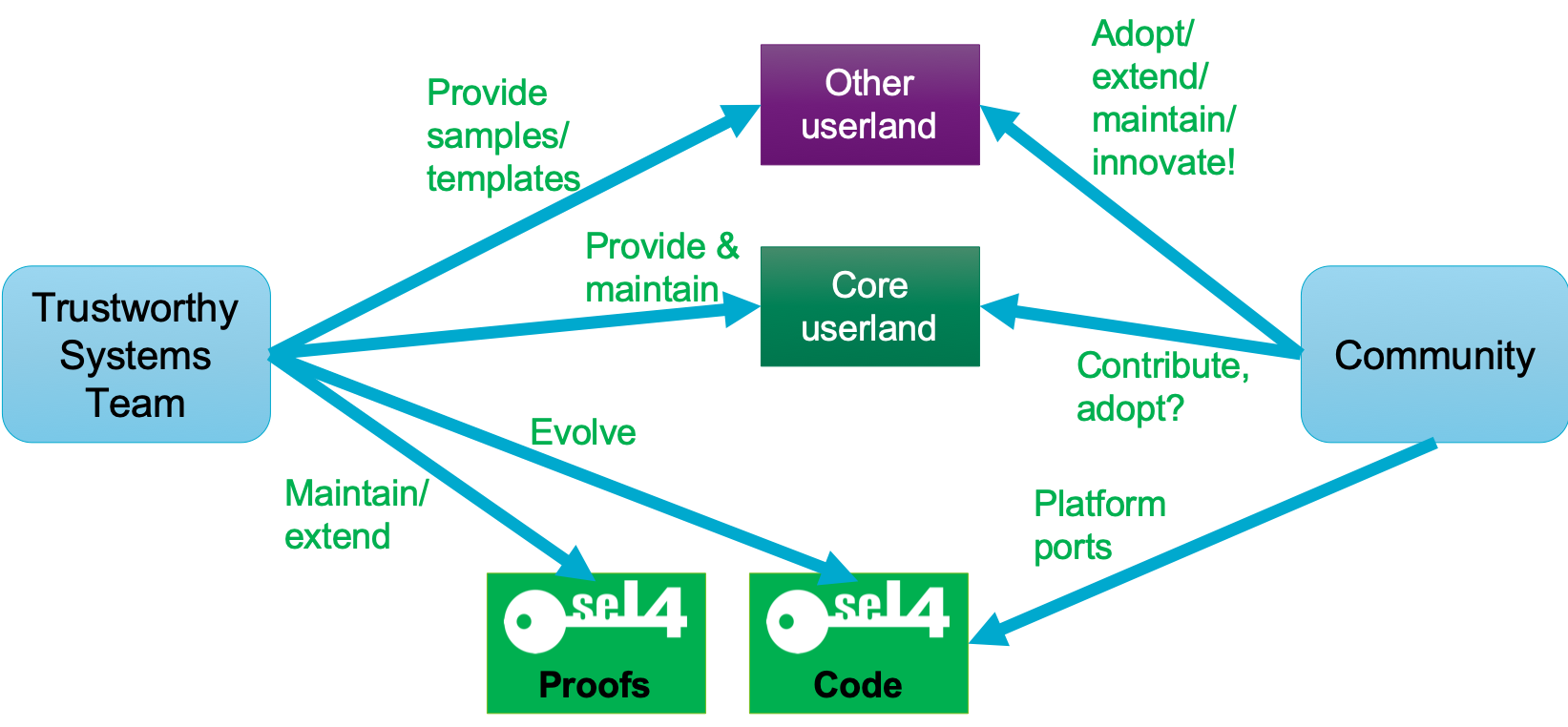
The seL4 developer community.
The (highly simplified) diagram above indicates this with the “Core userland” box – these are basic system services everyone needs. In fact, these typically correspond to components which Linux would have deep inside the kernel. We (TS) see it as our job to provide some of the core userland infrastructure, such as the CAmkES component framework, and maintain it at least initially. And we need to provide at least examples of others, such as well-integrated device drivers. However, we want the community to contribute to this, and hope that an increasing number of such parts will be adopted by maintainers from the developer community. The lower in the stack a component resides, and the more unique it is, the higher will be the bar for such adoption. This is because such core components must be designed right, meaning that maintaining them requires a very thorough understanding of how seL4 and seL4-based systems operate. Ideally, such core components should also be verified, but it will be a while until that becomes reality.
Things get easier with more high-level components, developer tools, libraries, or drivers for yet another NIC, once a performing example of a similar NIC driver exists. Some are still low-level enough for their Linux equivalents to live inside the Linux kernel (device drivers, crypto libraries) or are part of the “OS environment” (programming-language runtimes, shells, etc). But their dependence on the seL4 model is less, or there are good templates. Furthermore, there may be benefits from competing components with similar functionality (eg libraries optimised for small IoT systems vs desktops vs servers). Here we see our (TS’s) responsibility as mostly “showing the way” by providing sample code or designs and putting them out for community adoption.
The kernel itself will for the foreseeable future continue to depend strongly on our expertise. Besides ensuring purity of the design, this has a lot to do with verification: Very few people understand how a (seemingly innocent) change to the kernel will affect verification, and even our experts sometimes grossly underestimate the cost of changes. And, of course, when the kernel has changed, the proofs need to be updated, and that again is something few people can do at the moment. We do hope to get to the point where more non-TS community members can contribute proofs, but for the time being are committed to remain central to the kernel’s evolution.
We certainly welcome platform ports, and we are working on ways to make verification of a platform port easier, maybe semi-automatic. But that is still research!
And we do commit to an open process for evolving the kernel! This will be part of the duty of the technical steering committee of the Foundation, with representation of developers, which will run an open process for kernel evolution.
How does the seL4 Foundation operate?
Structure
The seL4 Foundation is set up as a Project under the Linux Foundation (LF) and follows the established structure of LF. This has the advantage that it is a familiar setup that is used by hundreds of open-source projects. It also means that we benefit from LF’s existing infrastructure (organisational and legal) as well as their existing networks for recruiting members. The structure is shown in the figure.
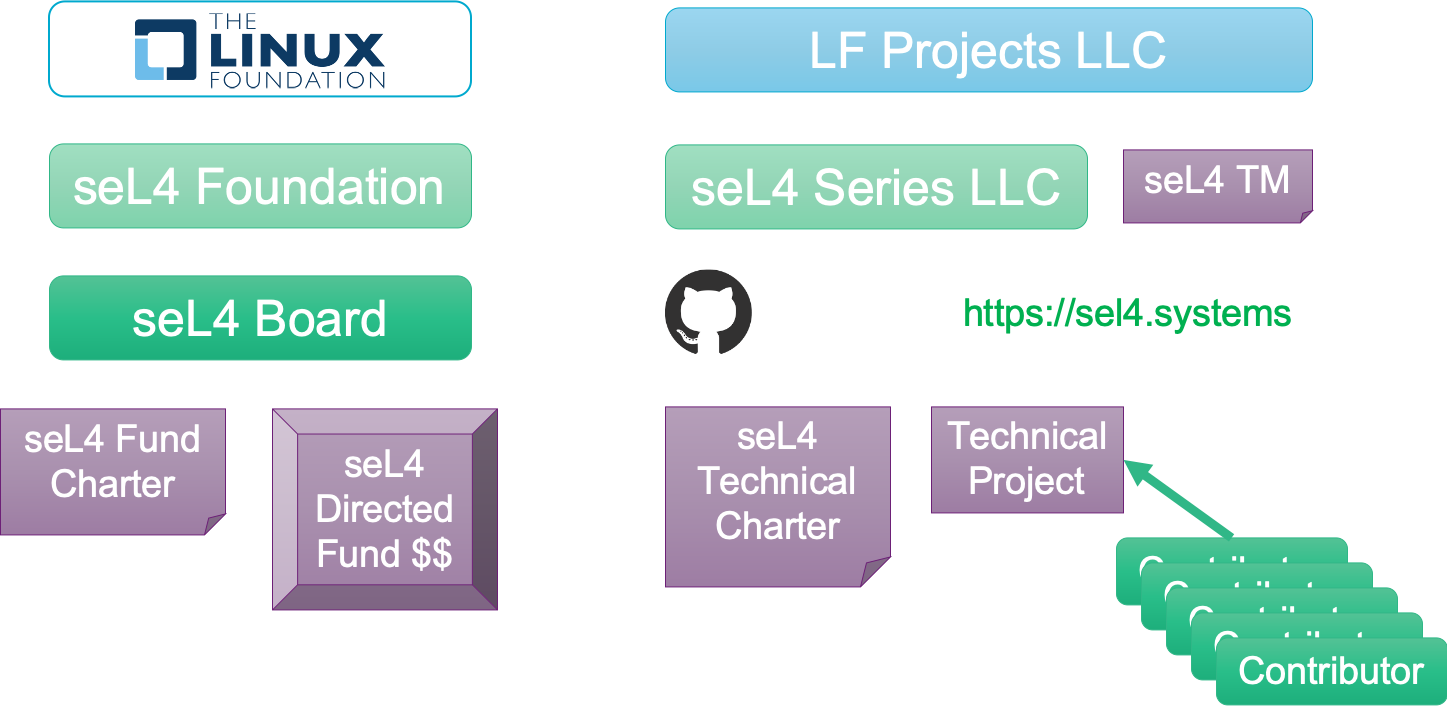
The structure of the seL4 Foundation under the Linux Foundation.
In line with LF, we clearly separate the Foundation’s governance from technical leadership and contributions. The Foundation has a Board that is responsible for the governance. In particular, it controls the “directed fund”, which is where membership fees go (minus a tax to LF). The directed fund can also receive extra contributions from members, it will especially be used to pool funds for the “big ticket” items I discussed above.
The technical activities are underneath the legal body of the “LF Projects LLC”, LF’s nonprofit company. Under it, the “seL4 Series LLC” is a virtual company for the seL4 Foundation. It holds the rights to the seL4 trademark and the seL4.systems domain name, and it hosts the GitHub source repos. Importantly, contributions to the source code no longer require a contributors license agreement (CLA). Instead contributors will provide a standard developer certificate of origin (DCO), as is standard with LF projects, removing the most bureaucratic part from contributions.
Membership and Board
Similar to the LF itself, the seL4 Foundation has different classes of membership, that model the LF’s. Note that to become a member of the seL4 Foundation, an individual or organisation must first be a member of good standing in LF (and pay their membership fees as well).
Fees for regular members are tiered by size, similar to LF, although our fees are lower than LF’s for small companies and somewhat higher for large ones. Premium members (who can be regular members of LF) pay extra in exchange for the privilege of having a guaranteed Board seat. Individuals and non-profit organisations (such as universities or other open-source foundations) can join for free as associate members. The Trustworthy Systems team, as the creators of seL4, have a special status as premium members without paying membership fees for five years.
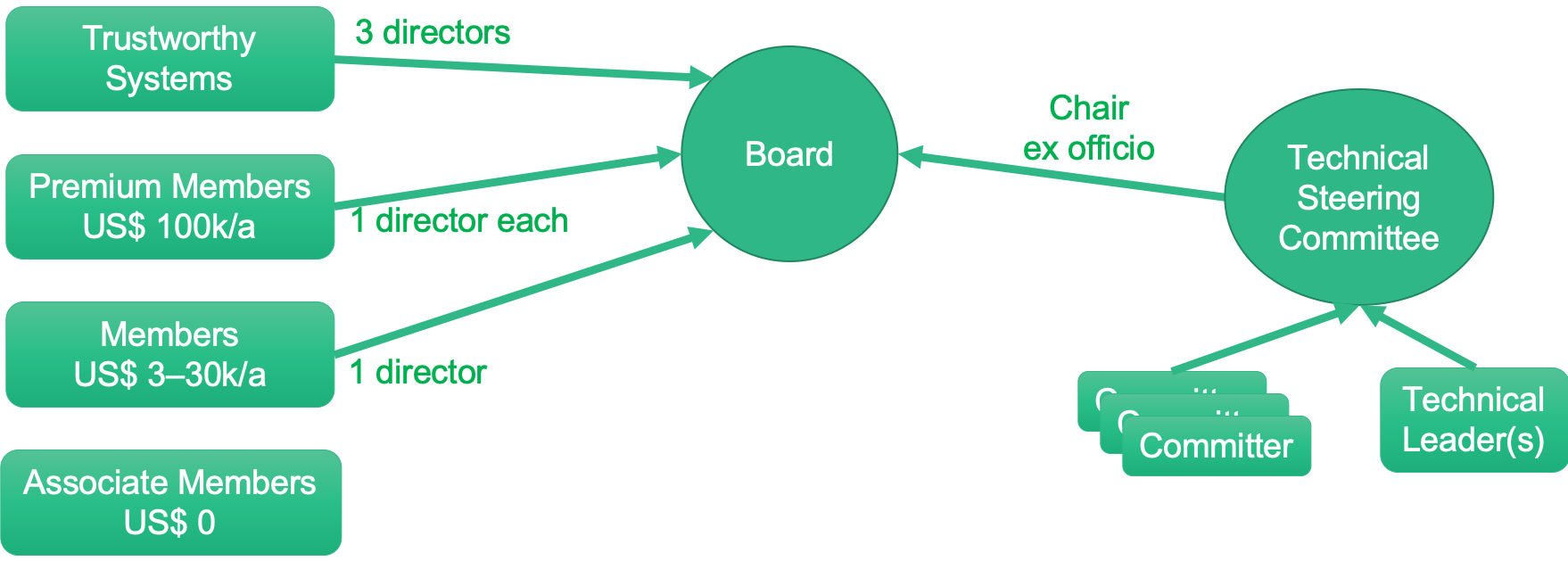
seL4 Foundation membership and Board.
The Board is composed of three members from TS, and one from each premium member. In addition, all regular members together elect a further Board Member. Finally there is the Technical Steering Committee, which is composed of committers and Technical Leaders (such as the non-committing leaders of TS) and is responsible for setting technical directions for the seL4 ecosystem. It has a chair, who is an ex-officio member of the Board.
The high representation of TS on the Board shows our commitment to making the Foundation work. We are not merely dumping this on the community and moving back to research. We are staying engaged, and have committed our resources for a minimum of 5 years. We chose this model in response to specific feedback from adopters.
Contributors, Committers and Technical Leaders
The Contributors make up the seL4 community – people who contribute code, documentation, tools etc to the seL4 ecosystem. A selected subset of Contributors are designated as Committers, these are the ones who can directly commit to the repository and accept pull requests.
Initially, the Committers are TS members who commit to seL4 code, proofs, docs, or userland code. We anticipate (in fact sincerely hope!) that we will soon be able to appoint a significant number of Committers from the community for non-kernel components. These will be approved by the Technical Steering Committee (TSC), which is made up of Committers and Technical Leaders.
One particularity of seL4 is that it has Technical Leaders who don’t commit code, but provide leadership on design and implementation issues (this includes yours truly). This is a very small number of people, who have the same say as Committers, including being part of the TSC, except the right to commit code.
The TSC elects a Chair, who is an ex-officio member of the seL4 Board, to represent the technical community.
Does this mean research on/for seL4 is done?
Not at all! We at TS will continue to do research that will feed into seL4, to ensure it remains the most advanced OS technology. In particular, our work on time protection as a principled way to prevent information leakage through timing channel has still a fair bit to go until it is production-ready and can make it into the mainline kernel.
This is in addition to research on architecture of secure systems, and tools and languages that make it easier to build high-assurance (ideally verifiable) components on top of seL4. This cluster of research will be an enabler for achieving our vision of not only a verified kernel, but verified core system components. One aim for the next few years will be to be able to build at least some simple systems with a completely verified trusted computing base.
We see this research as a central part of our on-going contributions to the seL4 ecosystem. And we hope that the Foundation will also lead to more collaboration in seL4-related research.
Ready to get involved?
The interim Foundation web site provides more details on how to join, including the full set of legal documents and a link to the LF interface for becoming a member.
But we need not only members, we also need active contributors, whether they are companies or individuals. If you want to be one of them, look at the Contribute page for projects looking for help, which can range from ports via enhancements to people becoming committers.
And if you want to deploy seL4 to secure your product, check out retrofitting and transitioning to seL4 for ways of doing this and the list of available userlevel infrastructure. And contact us if you are looking for commercial support for seL4, we can link you up with one of the growing number of companies providing this.
seL4 has been our team’s greatest achievement, but it didn’t fall out of the sky: it was the result of 15 years of research, and has evolved further for the past 10 years.
From the beginning, the design of seL4 has been driven by a number of principles. But a recent internal discussion about some fine points of the spec (as well as some discussions with externals) reminded me that some of these principles are in the minds of the designers but not really documented. This can lead to people (internal as well as external to Trustworthy Systems) arguing for APIs that are not in the spirit of seL4. Hence I’ll try to write up these principles.
The core drivers of the seL4 API are:
- Verification
- Minimality
- Policy freedom
- Performance
- Security
- Don’t pay for what you don’t use
Then there are a few non-goals:
- Stopping you from shooting yourself in the foot
- Ease of use
- Hardware abstraction
I’ll discuss them in turn.
Principles
These are the drivers of seL4’s design.
Verification
This is most obvious, and is seL4’s core claim to fame: we have a proof that the implementation adheres to the spec (functional correctness) as well as proofs of higher-level security properties. And with any changes to the kernel, the proof needs to be updated to re-establish functional correctness.
Verification has a significant impact on some design decisions – it shifts the trade-off between alternative designs. For example, concurrent systems are notoriously hard to verify, so we do everything to keep concurrency out of the kernel. Examples include the virtual TCB array and “long IPC” that was used in the original L4. These designs led to exceptions happening while in kernel mode. Such nested exceptions introduce concurrency, and are not acceptable for seL4, which is designed (and proved) never to trigger an exception inside the kernel. Interestingly, these problematic designs were already abandoned before we did seL4 (for simplicity and performance reasons), so verification did not force an inferior design. But it is an important factor in every design consideration, and certainly forces us to think carefully about every design choice. And this careful consideration has frequently led to a cleaner design.
A core challenge during kernel evolution is that re-verification takes much longer than the code changes that triggers it. We need to minimise the re-verification cost, so it is critical that code changes don’t make the life of our verifiers harder than necessary. In many cases, the impact of a code change on the re-verification effort is hard to predict, even for our experienced kernel engineers (and much harder for externals, which can sometimes lead to frustration, if externals suggest a change we have to decline as it would create a verification headache).
We handle this by keeping verification engineers in the loop when proposing changes to the kernel. This helps a lot, but does not eliminate surprises. Many verification challenges only show up when trying to re-prove kernel invariants, and frequently these lead to changes in the code, sometimes even the API, to make verification easier.
Minimality
This principle pre-dates seL4 by many years, and is the core principle of the original L4 microkernel, the ancestor of seL4 (and the whole L4 microkernel family). It was expressed by Liedtke in his seminal Hall-of-Fame paper On μ-kernel construction as:
A concept is tolerated inside the µ-kernel only if moving it outside the kernel, i.e., permitting competing implementations, would prevent implementation of the system’s required functionality.
This is a fairly categorical aim, and really an ideal, in that every kernel I’ve seen violates it at least a bit. But it is an excellent design driver, that has served the L4 microkernel family well for over a quarter of a century. With seL4 it has taken on additional significance: Verification cost grows roughly with the square of the code size, an excellent motivation for keeping it small!
Aspects of minimality are that we have no device drivers in the kernel (other than the interrupt-controller and a timer), and seL4’s extreme approach to memory management, where even kernel memory is managed by user-level code.
Generality
This is also an original aim of L4 (and microkernels in general): be a (trustworthy) foundation for a very large class of system designs. It is the principle that stops minimality from reducing the kernel size to zero.
In reality, there have always been use cases that have been better supported by the kernel than others. And much of our research over the years has been driven by addressing this: evolving the kernel to support a growing class of use cases well. For example, the biggest change to seL4’s functionality has been the introduction of a new scheduling model, with the aim of supporting a wider class of real-time (RT) systems, especially mixed-criticality systems (MCS), where critical RT code co-exists with untrusted code. As it turns out, the MCS kernel cleans up a number of other issues with the API, which make it an improvement even if your use case isn’t an MCS.
Policy freedom
This principle predates even the original L4 by decades. Policy-mechanism separation was explicitly stated as a principle in a 1975 paper about the Hydra OS, but the idea is already clearly contained in Brinch Hansen’s 1970 Nucleus paper, which describes the arch-ancestor of all microkernels. It really is a consequence of minimality and generality: if you want to keep your kernel minimal yet general, you must focus on the basic mechanisms, and build everything else on top.
seL4’s memory-management model takes a big chunk of (kernel memory-management) policy out of the kernel. Similarly for the MCS model, which introduces principled, capability-authorised user-level management of time as just another first-class resource.
Performance
Performance, especially of the critical IPC operation, has always been a core driver of L4 kernels: IPC performance is the master, as Liedtke expressed it in his ’93 paper Improving IPC by kernel design. The reason was that attempts to build usable systems on earlier microkernels, especially Mach, failed because the kernel introduced too much overhead. Liedtke’s original kernel showed that microkernels can be fast, and allowed the construction of performant systems on top.
From the beginning, seL4 was designed to be suitable for real-world use, and we therefore considered an uncompromising design for performance as essential. My message to the team at the beginning of the project was “I will not consider the project a success if we lose more than 10% performance compared to our fastest kernel to date.” At the time of the original seL4 paper, we were right at that 10% limit. But further optimisation got us to the point where seL4 became faster than all our earlier kernels.
This became the tagline for seL4: Security is no excuse for bad performance! Besides its verification, performance is what sets seL4 apart from all other microkernels – it really sets the benchmark.
Performance: Focus on the hot code paths
This performance aspect results from the observation that in any system, some operations are used more frequently than others, and overall performance can be maximised by shifting cost from the frequently used “hot” operations to infrequently-used ones.
The prime example of a hot operation is IPC: in a microkernel-based system, all system services are provided by user-level servers that are invoked by IPC, so this is the predominant operation. Notifications, which are semaphore-style synchronisation primitives, are also frequently used. Handling of exceptions and interrupts is also frequently performance-critical (eg exceptions are used for emulation/virtualisation), but exceptions are mapped onto IPC and interrupts onto Notifications, so optimising those will benefit exception and interrupt handling.
But not all of seL4’s IPC functionality is equally performance-critical. IPC allows transferring capabilities, which is an inherently more costly operation (requires Cspace manipulations). If the “simple”, function-call-style IPC can be made faster while slightly penalising the more complex variants, then this is a winner. It’s the idea behind the IPC fast path, which does the minimal checking that all its preconditions are true, and then executes a very tight code sequence.
Where is the boundary between “hot” and “cold” code? A good way to think of this is in term of changes to kernel state, i.e. the set of data structures held by the kernel. Every system call changes kernel state (even if only to update accounting information). But there are simple invocation sequences that return the kernel into what I’ll call the same logical state as before the sequence began, meaning that the kernel states only differ in accounting information (execution time charged to threads).
For example, the basic RPC-like server invocation (aka protected procedure call) results in the following changes of logical kernel state, assuming we start with the server blocked on its request endpoint in the receive phase of seL4_ReplyRecv():
- client performs seL4_Call(), kernel changes client state to blocked
- kernel sets reply object state
- kernel moves scheduling context from client to server
- kernel unblocks server, which executes the request
- having handled the request, server performs seL4_ReplyRecv() on the reply object to respond to the client, kernel blocks server
- kernel returns scheduling context to client
- kernel unblocks client, which continues executing.
As far as the kernel is concerned, we’re now back at the initial logical state, and state change was temporary, and should be made fast. This is in contrast to typical Cspace manipulations: these are reversible too (eg. a capability can be transferred and later revoked), but not in a simple (in the user view primitive) operation such as a round-trip IPC. An IPC that transfers a capability will leave the receiver’s Cspace changed, and that change is typically long-lived. It’s also inherently more expensive than a basic IPC.
Such logical-state–preserving operations may be accelerated by a degree of laziness, as exemplified in the scheduler optimisation called Benno scheduling: When unblocking a thread on an IPC receive, we don’t immediately insert it into the ready queue, as it is likely to be blocked again soon, which would undo the queue operation just performed. Instead we only insert the presently running thread into the ready queue if it gets preempted. This avoids any queue-manipulation operations during the logical-state–preserving IPC round-trip.
Performance: Don’t pay for what you don’t use
While much of the above principles are discussed in several places, including our 20-years experience paper, this aspect is somewhat buried inside the brains of the designers, but is important for understanding some design decisions. A feature that may benefit a particular use case may have a (small but noticeable) cost to other, frequent use cases.
An example is the “long IPC” that was a feature of original seL4. It supported copying of large message buffers by the kernel, which seems like a good optimisation for sharing bulk data. But the only actual use case was Posix emulation (specifically broken aspects of Posix). But there is a cost even if you don’t use it: the performance cost of extra checks on the IPC path, and the complexity cost of the kernel having to deal with nested exceptions (page faults happening during long IPC). In the end we decided it was a bad design, and a gross violation of minimality (the copying can be done by a trusted user-level server).
A similar argument is behind not supporting scalability of the kernel for large number of cores. On closer consideration, this is a bad idea: migrating even a single cache line from one end of a manycore chip to the other takes 100s of cycles, of the order of a the cost of a complete IPC. So, if you really want this, you should implement it at user level (i.e. a multikernel design). Sharing a kernel image makes sense where the cost of using a multicore configuration would be significantly higher when implementing it at user level, as is the case in a closely-coupled multicore, where the cores share an L2 cache. This is the case we support, while we have no plans scaling the single-kernel-image design to loosely-coupled multicores (not sharing an L2).
Security
Security was always high on the list of requirements for L4 kernels, although in the past came in many cases with a degradation in performance and flexibility. Even before seL4 it was the reason for adopting capabilities for access control, first in our OKL4 microkernel.
In seL4 security is a core principle, the kernel is fundamentally designed for providing the strongest possible isolation. It is the main driver behind seL4’s radical approach to resource management: after booting, the kernel never allocates any memory, it has no heap. Instead, when performing an operation that requires kernel memory (e.g. creating an address space, which requires memory for page tables) the caller must provide this memory explicitly to the kernel (by a process called retyping, which converts user-controlled Untyped, i.e. free, memory into kernel memory).
The model makes management of kernel memory the responsibility of (trusted and protected) usermode processes. The model not only enhances minimality and policy-freedom, it is the core enabler of our proofs of security enforcement. Its aim is to make it possible to reason (formally) about the security properties of seL4-based systems.
Most recently we have taken a step further in extending isolation (and thus security) to timing properties, as a principled way of eliminating timing channels. This is still very much a research topic and not yet ready for the production kernel.
Security: Least privilege (POLA)
An important part of (design for) security is the principle of least privilege, also known as the principle of least authority (with the catchy acronym POLA). It means that any component should only ever have the privileges (power) it needs to do its job, but not more. The fine-grained access control provided by capabilities is a great enabler of POLA, which is why we switched to caps even before seL4.
Security: Delegation and revocation
Least privilege is potentially at odds with performance, as a simple way to minimise authority given to a component is to have it to obtain explicit approval from an external (trusted) security monitor for everything it does – clearly not a good approach. Furthermore, a security-oriented design is likely hierarchical: a subsystem has limited privileges, and it contains sub-sub-systems with even more limited privileges. Enforcing such internal boundaries in subsystems should not be the duty of the top-level (most privileged) component.
This calls for mechanisms for delegating the exercise of (reduced) privilege. If a component has rights to a resource, such as physical memory, it should be able to create an (isolated) subcomponent that with the same or reduced rights to that resource. And it must be able to revoke the delegation.
Capabilities, as seL4 provides them, support effective delegation of (partial) privilege. For example, if you want to have a subsystem that manages a subset of physical resources autonomously then you can supply it with some Untyped memory, which it can then manage without interfering with other components’ memory use. If you want to restrict the component (eg an OS personality) further, you can instead supply it with with caps to pools of TCBs, frames, address spaces etc. It can then manage the pools, but would have to appeal to a higher authority to move memory between the pools. In short, the authority give to the subsystem can be made to match the system’s resource management policy.
Anti-Principles
There are a number of properties many people would like from the API, but we are explicitly not providing them for reasons I will explain.
Stopping you from shooting yourself in the foot: not the kernel’s job
In fact, the kernel does its best not to limit the size of guns you can use; aiming the gun is your problem (see policy-freedom). Specifically, it’s the system-designer’s job to ensure that dangerous tools can only be used by those who are trusted (ideally proved) to use them responsibly.
However, stopping someone without explicit authorisation from shooting you in the back is the kernel’s job; that’s a core aspect of security.
Ease of use: not a goal of a good mirokernel API
seL4 is a minimal wrapper around hardware that provides just enough so you can build secure and performant systems on top. Consequently, you shouldn’t expect it to be easier to use than bare metal.
Usability is important for building practical systems, of course, but the way to achieve it is by providing higher-level abstraction layers. These are inevitably optimised for particular classes of use cases, introduce policy and reduce generality. This is fine, as the abstraction layer can be replaced if you want to implement a different use case (see the definition of Minimality).
Hardware abstraction: not a goal of the seL4 API
This should be obvious from the above: HW abstraction supports ease of use and introduces overhead. But it will also hide details that are important in some cases.
An example is memory management. Different architectures specify different page-table formats. Trying to fit them under the same abstraction would inevitably lose detail, and prevent seL4-based systems from making full use of whatever hardware support there may be. An obvious example would be architectures that use hashed page tables, such as certain versions of the Power architecture. Forcing a hierarchical page-table structure would imply inefficiencies.
All presently supported architectures use hierarchical page tables, so we could be tempted to ignore that particular aspect. But even on our supported architectures (x64, Arm and RISC-V) there are subtle difference in the semantics of page table which would be unwise to hide.
Trade-offs
Like just about everything in systems, our principles are frequently in conflict, meaning it is necessary to find a design that represents the best trade-off between them. Especially performance and verifiability frequently run against an otherwise attractive choice. Conversely, performance considerations occasionally lead to non-minimal features (and increased pain for our verifiers).
Clearly, these principles, other than security and verification, are not absolute. In this sense, good microkernel design is still an art, and understanding the trade-offs is key to good results. But these principles are excellent and time-honoured drivers of good design.
This question comes up again and again, and from talking to people, I realise that there are a lot of misconceptions about seL4 licensing and what it implies, in particular in terms of the infectiveness of the GPL. I tried to address this at my talk at the recent seL4 Summit, and will repeat and expand on what I said there.
Spoiler: The GPL license of seL4 has even less impact on you than the license of Linux would. It is not forcing any licensing conditions of anything that is of any value to you, and most likely not on anything you should be touching at all.
Licenses
The seL4 kernel is licensed under GPLv2, version 2 of the Gnu General Public License – exactly the same license that is used for the Linux kernel. The core implication is the same as for Linux: Work derived from the kernel (be it additions, modifications or other enhancements) become automatically GPLed,  but anything running on top of the kernel (i.e. in usermode) is unaffected and can be under any license.
but anything running on top of the kernel (i.e. in usermode) is unaffected and can be under any license.
We specifically license any usermode code we developed from scratch (libraries and components such as drivers and file systems) under the permissive 2-clause BSD license, to allow people to build arbitrary systems on top of seL4 and license them as they see fit. We do license some generally useful tools under GPL to maximise the benefit to the community, but no-one who uses seL4 is forced to use those tools.
A similar story holds for proofs: Our proofs about the kernel itself are under GPLv2, while proofs about user-level code are a mixture of GPLv2 and BSD licenses.
Implications
So, while in an abstract sense, things are exactly as in Linux, in practice there is a huge difference: GPL infectiveness in seL4 is only limited to code you should most likely not touch at all. This is a result of seL4 being a microkernel: the kernel only contains code that must run in the privileged mode of the hardware, everything else is left to user mode. This means that everything that does anything “useful”, such as file systems, device drivers, network protocol stack, resource management, definition of security policies, etc, is left in user mode, and can therefore be under any license. The kernel (after booting) is just a fast context-switching engine that happens to enforce isolation with the strength of mathematical proof.
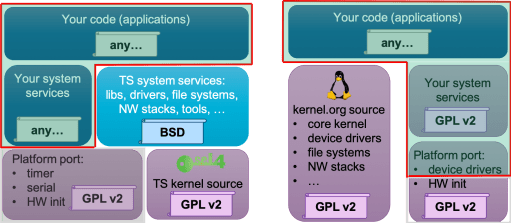 This is in stark contrast to Linux, where all of the things listed above are inside the kernel (and thus subject to the GPL). As the figure shows, with seL4 all the “interesting” code, in particular anything that could be valuable IP of the adopter of seL4, is at user level, and can be under any license. This specifically includes device drivers, which might reveal valuable hardware IP – with seL4 these can be kept closed. With Linux, you’d be forced to open-source them. Similarly, if you add a new file system or improve an existing one, provide improved network protocols, etc, you can do this without open-sourcing with seL4, but not with Linux.
This is in stark contrast to Linux, where all of the things listed above are inside the kernel (and thus subject to the GPL). As the figure shows, with seL4 all the “interesting” code, in particular anything that could be valuable IP of the adopter of seL4, is at user level, and can be under any license. This specifically includes device drivers, which might reveal valuable hardware IP – with seL4 these can be kept closed. With Linux, you’d be forced to open-source them. Similarly, if you add a new file system or improve an existing one, provide improved network protocols, etc, you can do this without open-sourcing with seL4, but not with Linux.
In short, with seL4, any IP of real value can be licensed under conditions chosen by the owner, while in Linux, much IP would have to be open-sourced. This includes everything in the “your system services” box in the diagram, as well as the driver part of the platform-port box below. Compared to the size of the seL4 kernel (order of 10kLOC), this is huge (typically 100s of kLOC), much bigger than it might appear from the simple diagram.
In fact, you shouldn’t ever modify any of the GPLed kernel code, unless you’re doing a new platform port. The reason is simple: if you modify seL4, you invalidate verification. And the verification is the real value of seL4 (besides minor details such as seL4 being the fastest of its kind, and also the most advanced 😉) so why would you want to throw it away? With broken verification, it’s no longer seL4!
What actually must be open-sourced with seL4 is some minimal platform support. But this is simple and pretty boring boilerplate stuff:
- You’ll need a simple timer driver (so the kernel can perform time-slice preemption). A typical example consists of less than 20 LOC (split between header and implementation body). This is if your platform has a timer device that’s different from any existing supported platform, and there’s a good chance there is one already. Typically you’d lift that code out of Linux anyway.
- You’ll need a serial port driver (used for kernel debugging, but not in the production kernel). A typical example is less than 10 LOC! Again, it may already exist or you borrow it form Linux. No valuable IP anywhere near.
- Then there’s an interrupt controller. That’s another 500 LOC or so spread over multiple files. Much of it is addresses, more addresses and register layouts, and some generic code that probably exists already.
- You may also need some code for handling the System MMU (SMMU) and cache management functions, but those are becoming increasingly standardised.
As I said, none of this is IP of any value, and chances are that most of it exists already and you won’t have to do much more than defining the memory layout of your platform. A concrete example is the patch needed for supporting the i.MX8: about 20 lines of definitions in total. Scared of “giving it away”? Why would you?
[Thanks Kent McLeod for digging out the code examples.]
Why are we doing it this way?
People sometimes suggest we should just change the license to BSD. This would be a really bad idea! To demonstrate what I mean here I asked the Summit participants who had done a project involving Linux before. Unsurprisingly, almost everyone put their hand up. I then asked who had done a project with BSD Unix. Two academics raised their hand.
This says a lot about the power of licensing. Experts generally agree that BSD Unix was technically superior to Linux. Yet Linux dominates the world, and BSD Unix exists in academia and some niche applications, the only significant usage is its descendant Darwin, which forms the core of macOS and iOS (but not many know this).
Why did this happen? The reason is that, lacking strong leadership and using a permissive license, BSD forked into oblivion.
We will not allow the same to happen to seL4. We want seL4 to grow and become the one and only choice of OS for security- and safety-critical systems. The GPL is part of that strategy (and the forthcoming seL4 Foundation is the other).

Space satellites are expensive. Part of that is the launch cost, but that cost is dropping dramatically to tens of k$/kg. This, combined with the growing demand for micro-/nano-satellites, is increasing the sensitivity to other cost factors.
One of the big cost factors is the computer system that’s controlling the satellite. This may seem surprising, given that modern processor chips cost a few dollars. However, space is a very hostile environment, not only for people, but also for electronics. High-energy ionising radiation hitting a CMOS chip is creating clouds of charge that can flip bits in memory, caches or CPU registers, so-called single-event upsets (SEUs). Satellites typically use radiation-hardened processors that are not susceptible to SEUs. The drawback of these processors is that they are very expensive, typically 100s of k$ for a single one! And they run at low clock rates (few 100 MHz) and are based on old, power-hungry silicon technology.
What does this have to do with seL4?
What can an operating system (OS) do to address hardware cost? More than one might think at first. The core of the problem is that software relies on hardware operating correctly, i.e. according to a specification, namely the instruction-set architecture (ISA). SEUs result in hardware behaviour deviating from spec (unpredictable bit flips).
Traditional fault-tolerant systems

Traditional triple-modular redundancy (TMR) fault-tolerance.
The traditional way of protecting against such random faults is redundancy: the system is replicated, and the replicas check each other to detect (and ideally correct) faults. Such redundant hardware configurations have been used for decades in critical systems (e.g. airplanes or nuclear power plants). They typically use 2- or 3-way redundant hardware, called dual- or triple-modular redundancy (DMR or TMR, respectively). DMR tends to be cheaper but can only detect divergence (and then pull the plug), while TMR can use a majority vote to detect the faulty replica and correct by either turning the faulty one off (i.e. downgrading to DMR) or restarting it.
But they are expensive not only because of replicated hardware, but also as they require special voting hardware that checks for divergence among the replicas. Also, replicas typically have to operate in lock-step, which introduces high overheads.
Enter cheap multicores
The abundance of cheap multicore processors, driven by the mobile-phone market, is a game-changer here. We now have redundant (at least in terms of processor cores) hardware, that is cheap, high-performance and very energy-efficient. Can these be leveraged for making systems fault tolerant?
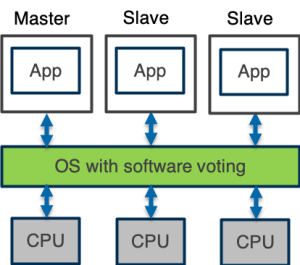
Multicore-based TMR configuration with non-replicated OS.
A number of recent proposals have explored this, typically along the lines of the diagram on the left: A shared operating system (or hypervisor) presents the multicore system as a logical single core that transparently replicates application software, and does the voting. This approach can effectively protect against faults in the application software. The problem is that the non-replicated OS is still vulnerable to SEUs – any bit-flip in OS data or instruction memory can cause the system to fail. Rather than real protection, this reduces the vulnerability to a relatively small memory region (assuming a slim OS kernel or hypervisor).
The advantage is that this is much cheaper (and more energy-efficient) than either traditional hardware replication or using rad-hardened processors.
Redundant co-execution with seL4
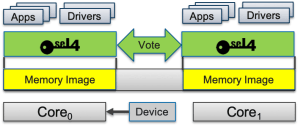
RCoE even replicates the OS kernel, and thus all software (except the minimal shim to non-replicated devices).
We have recently pioneered a new approach that combines the benefits of the above, which we call redundant co-execution (RCoE), and have implemented this in seL4. The idea is shown in the diagram (for simplicity as a DMR configuration, but we can do an arbitrary number of replicas, including TMR): We also replicate the OS kernel, which is now aware of running in a replicated configuration. It compares (votes) the inputs and outputs of all kernel replica whenever entering or exiting, as well as configurable points within the kernel. This now extends the sphere of replication to practically the whole system, minimising vulnerabilities.
Applications get transparently replicated with RCoE (just as with the simplified model above). As seL4 is an extreme case of a minimal microkernel, where all traditional OS services, including device drivers, run as usermode programs, these get automatically replicated.
The one exception are peripherals that are (inherently) non-replicated, such as network interfaces. Such a peripheral has a single set of hardware device registers which the device driver uses for controlling I/O through the device. This represents a residual vulnerability, if bit-flips happen while accessing those registers. We keep exposure to the absolute minimum: When reading from a device register, a low-level shim immediately copies the data to replicated buffers, and then hands control to the (replicated) drivers which each operate on their own buffer, any divergence can be detected at that point. Similar, when writing to a device register, the shim compares the replicated output buffer, and then immediately copies to the device. The few instructions required for this is the only part where a bit-flip could happen undetected.
Virtual machines
While seL4 is a microkernel, it works pretty well as a hypervisor. So while RCoE approach transparently replicates applications, these do not have to be native seL4 apps, they can be virtual machines (VMs). Such a VM can run a complete Linux system as a guest, in which case the Linux system will also be transparently replicated. Obviously, in such a configuration, replica voting is very course grain, as the seL4 kernel gets rarely invoked during VM execution.
A typical configuration has the more critical code running natively on seL4 (with frequent voting), while less critical code can run inside the Linux VM.
Two variants
We implemented RCoE on Intel x86 processors as well as on Arm processors (although virtual machines we presently only support on x86). We have also designed and implemented two different versions of RCoE, a closely-coupled one, where for voting the replicas are synchronised to the exact instruction (while executing asynchronously between votes) and a loosely-coupled version, where replicas of user-mode components are unsynchronised when voting. These represent different trade-offs of performance, vulnerability and restrictions on application characteristics.
Does it work?
It works pretty well. We ran a large number of experiments where we introduced random faults in physical memory. We injected enough faults to observe 1,000 errors (which took hundreds of thousands of fault injections). Our default configuration (where voting happens on kernel entry and exit, as well as device communication) handled all but a handful gracefully, i.e. detecting an error before the system would produce erroneous outputs. We could also clearly see a performance-vs-dependabilty tradeoff at work, where making the voting more frequent would increase dependability at the cost of reduced performance. With enough effort (i.e. checking) faults can be made close to negligible.
We could also show that the TMR configuration can effectively downgrade to DMR and continue operating with the faulty replica taken off-line. The cost of this transition is only of the order of a millisecond.
At what cost?
Performance overhead of the default configuration (which eliminates almost all uncontrolled failures) is of the order of 30–100%, compared to unprotected single-core operation. In other words, a redundant system takes 1.3–2 times the time of the unprotected single-core system to execute a workload. In terms of energy, this means that the TMR configuration will consume 3×1.3–2, or 4–6 times the energy of unprotected execution.
To put this in context: The rad-hardened RAD750 processor (costing 100s of k$) delivers 240 DMIPS at 133 MHz, or at most 40 DMIPS/W. Our SabreLite board produces 2,000 DMIPS per core at 800 MHz. Using three cores (for TMR) with a 2-times performance overhead it still delivers five times the DMIPS/W of the RAD750. In other words, being able to use a cheap, low-power multicore processor comes out far in front of the rad-hardened processor despite the overhead.
And in terms of cost, it ends up >10,000 times ahead. So there really is an opportunity to reduce cost of satellites with seL4!
Find out all the details
Full details of this work are in a paper published last June in DSN, the top publication venue for dependability and fault tolerance. It contains the complete technical details and complete evaluation. If you want even more gory detail, it’s all in Yanyan Shen’s PhD thesis.
Can I try it out?
We’ll make the software available for download from the project page soon.
But keep in mind, this is a research prototype so far, and would need some more engineering for real deployment. Ideally the kernel with redundancy support should be verified, to achieve a degree of dependability approaching that of (expensive and slow) reliable hardware.

A week ago, on 29 July, we at Trustworthy Systems celebrated seL4 Freedom Day, the 5th anniversary of the open-sourcing of seL4. Furthermore it was seL4’s 10th birthday – the anniversary of the completion of the first functional-correctness proof (of seL4 and of any operating system), showing that the implementation was bug-free.
This anniversary prompts me to reflect on what happened with seL4 in those 10 years, what we have achieved with it, how it evolved, and what the on-going challenges and future directions are. I hope I’ll find the time to follow this up with more in-depth examinations of some of those developments.
seL4 was build from the beginning with three objectives in mind, all of equal importance:
- to have its implementation formally proved correct (which is what we mean when we say “verified”)
- to solve long-standing problems with resource management in microkernels (and OSes in general)
- to be suitable for real-world use.
I’ll look at how seL4 addresses all three.
The Proofs
The defining feature of seL4 is clearly its verification story, starting with the functional correctness proof. And, amazingly, it’s still fairly unique in this respect, much more so than I had assumed when we first created it. I had estimated we’d have a window of 3–5 years before someone created another verified OS kernel. Turned out I totally over-estimated the competition 😉.
While there are now a number of other OSes around with some sort of a code verification story, they are almost all toys (notwithstanding what their authors might be claiming). The only verified OS I have heard of that seems to have a defensible claim of being suitable for real-world use is the recently verified PROVENCORE system from French company Prove&Run. And even this system has a much narrower target domain: it’s designed for use in TrustZone-based trusted execution environments (TEEs), with a static architecture, and gets away with a very simple protection model. seL4, in contrast, is fully dynamic, and can support arbitrary secure system architectures, thanks to its flexible capability-based access-control model.
More proofs
The original proof showed that seL4’s C code was a correct implementation of its formal specification (mathematically speaking the code is a “refinement” of the spec). This was done for an ARM11 processor (32-bit Arm v6 architecture). There were a few missing bits and pieces, most have been completed by now.
The main remaining hole is that the kernel’s boot code is still not verified. This means that our proofs say that if the kernel boots into a safe state, it will remain in a safe state. The boot-code verification needs to show that the kernel actually gets into a safe state initially. Clearly this proof is overdue (and we are working on it as a background activity).
Beyond that, much progress has happened on the verification side:
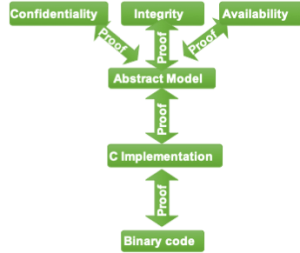
seL4 proof chain.
- We proved (in 2011) that the kernel is able to enforce integrity, i.e. prevent a subject from modifying data without explicit authorisation. This shows not only that the spec is correctly implemented, but that it has the desired property (i.e. integrity enforcement).
- We proved (in 2013) that the separation-kernel configuration of seL4 enforces confidentiality in the (very strong) information-flow sense, meaning it can prevent unauthorised information leakage, including through covert storage channels. This is the complement of the integrity property, showing that (direct or indirect) reads only succeed if authorised. Note that the formalism has no notion of time, so this infoflow property cannot preclude timing channels (timing-channel prevention are one of our present foci).
- We developed (in 2013) a translation-validation toolchain which proves that the binary (produced by the compiler and linker) is a correct translation of the verified C code. This means we do not have to trust the compiler (we use gcc), nor our assumptions on C semantics, drastically reducing the trusted computing base (TCB) of our verification.
Together, these proofs show that not only is the kernel’s implementation free of bugs, and that the compiler did not introduce bugs on its own, but that the kernel enforces security in a very strong sense, and that property applies to the binary that is executing on the silicon.
We finally performed (in 2011) a complete and sound worst-case execution-time (WCET) analysis of seL4. To my surprise, this was the first such analysis performed of a protected-mode OS kernel in the literature, and is a core ingredient making seL4 suitable (and superior to any other system) for use in safety-critical real-time systems where not all code is trustworthy (so-called mixed-criticality systems, MCS). We have meanwhile improved this analysis, using the translation-validation framework to link properties proved about the source code to the binary. This improves the assurance of the whole process, and allows us to leverage our correctness proofs to bound loops and eliminate infeasible paths in the binary.
More architectures
The original proofs were done for Arm v6, and have since been ported to Arm v7. We added verification of the Arm v7a virtualisation support (“hyp mode”) in April’17. Arm v7a remains the architecture with the most complete verification story. This made seL4 a verified hypervisor.
In July’18 we completed the functional correctness proofs for x64, making this the first verified 64-bit version of seL4.
And before the end of this year we expect to complete the functional-correctness proofs for the 64-bit RISC-V architecture, as well as the translation-validation toolchain that carries those proofs through to the binary.
Still to do
There are a number of things still to be completed. I have mentioned kernel initialisation earlier. There are also a number of parts that were not verified to the same degree as the rest of the kernel, in particular MMU management. A PhD thesis on formalising the MMU has just completed, so this is mostly done.
We are also working on verifying the multicore version of seL4. This is challenging because of seL4’s uncompromising design for performance, which means that the implementation is racy. Removing races would make the problem far easier to solve, but we won’t accept the performance compromises this would imply. After all, our motto is “security is no excuse for poor performance”, a core differentiator to other high-assurance systems.
Resource Management
We developed seL4, starting in 2004, on the back of 10 years of experience with high-performance L4 microkernels, including the OKL4 kernel from Open Kernel Labs, which developed out of our L4-embedded kernel and ended up on billions of Qualcomm modem chips. Another fork of L4-embedded is what now runs on the Secure Enclave of all Apple iOS devices.
Issues of earlier L4 kernels
During that time we learnt about a number of shortcomings in the original L4 design. Several of those were already fixed in our L4-embedded kernel (a fork of the Karlsruhe Pistachio kernel), including overcoming the restrictive nature of the overloaded synchronous IPC, and complementing it with an asynchronous notification mechanism. The IPC model kept evolving with seL4, until it finally settled into a protected procedure call, complemented by Notifications which are binary semaphores.
The removal of a number of non-minimal features, including “long” IPC, and IPC timeouts, had already begun with L4-embedded and was adopted in seL4. We further eliminated a number of implementation tricks that had outlived their usefulness, including the virtual TCB array, and the process-kernel design.
By the time we started with seL4, the L4 community had reached a consensus that the model of addressing IPC to threads needed to be replaced by capability-based addressing and port-like IPC endpoints. (This was helped along by Jon Shapiro’s observation that the traditional L4 model had covert storage channels.)
Capabilities also cleanly solved another issue with original L4, that of limiting communication. The original model relied on an (inflexible) process hierarchy and redirection to a monitor process (“chief”) to limit data flow. Capabilities provide a cleaner, simpler and low-overhead model: Having a privilege does not in itself imply the ability to share that privilege, an additional grant right is needed to pass on capabilities.
Our 2016 paper discusses these issues in detail.
Untypeds
An issue that remained unresolved pre-seL4 was principled management of kernel memory. Prior L4 kernels had a kernel heap for allocating kernel data structures, which lead to poor isolation and the potential for denial-of-service (DoS) attacks; some kernels introduced kernel memory pools and quota as an unconvincing fix. Kevin, who had experimented with various models for years, developed the present seL4 model: The kernel has no heap whatsoever, and a strictly bounded stack; it never allocates memory after boot. Instead, user-level code is required to explicitly provide memory to the kernel for any operation that requires meta-data allocation. The mechanism for doing this is seL4’s Untyped memory, and retyping it onto kernel-object types.
This model of retyping Untyped memory is extremely powerful. It is a very simple abstraction for managing (spatial) resources: A security domain can only create kernel objects out of whatever amount of Untypeds it is given. In particular, this makes it impossible for an agent to interfere with a domain’s ability to create kernel objects, thus avoiding DoS attacks by construction.
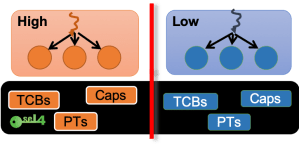
seL4’s memory management model extends user partitions into the kernel
Furthermore, the need for usermode to provide working memory to the kernel means that partitioning userland will implicitly lead to partitioning of kernel memory, a very powerful property. This has been a major enabler of our isolation (integrity and confidentiality) proofs.
The downside is that the model is tricky to use and makes it easy to shoot yourself in the foot (as many students will attest). However, it is not the job of the microkernel to protect your foot from yourself, it is to protect you from malicious code by providing strong isolation. This is exactly what seL4 does extremely well.
Time
The biggest remaining hole in the resource management story of the original seL4 had to do with managing time (as stated in the 2016 paper). L4 traditionally had a weak (if any) temporal isolation story, and at the time of the design of seL4, this was left in the too-hard basket, and we used a fairly naive approach to scheduling. This was always meant to be addressed later.
Temporal integrity
We fixed some minor issues when performing the WCET analysis of the kernel, including replacing the (in average fast but worst-case extremely slow) “lazy scheduling” by Benno scheduling (which is as fast in average without a pathological worst case).
But the main problem remained: no accurate accounting for time, especially with shared servers. This meant that seL4’s support for hard real-time (RT) systems was limited: only in a narrow set of scenarios could it provide the required integrity guarantee, namely that a critical thread will be able to meet its deadline.

“Passive’ servers execute on a client’s donated scheduling context.
We finally addressed this cleanly by evolving the model of scheduling contexts (developed early by the Dresden group for a pre-capability kernel) and integrating it with seL4’s capability model. This finally made time just another resource authorised by capabilities, and thus a first-class resource managed in a principled fashion. Scheduling concepts are now first-class kernel objects; they represent the right to access a share of the CPU.
This model is implemented in the MCS kernel, called so because it provides the right mechanism for supporting MCS, including the ability to guarantee time to critical threads in the presence of untrusted high-priority threads. It is the first capability-based model of managing time in a way that is suitable for hard real-time systems (together with the concurrent work on the Composite OS; KeyKOS “meters” were also time capabilities but not suitable for hard RT).
The MCS kernel is, for now, in a branch. The reason is our commitment that changes to the mainline kernel must not break verification. The MCS model requires very invasive changes to the kernel, which means re-verifying is a lot of work. However, this work is nearing completion, and we expect MCS to be merged into mainline by the end of this year or early next.
As it is the future of seL4, and has a number of other improvements that simplify many use cases, we strongly recommend new developments to be based on MCS.
Timing channels
The MCS kernel solves temporal integrity, but confidentiality remains unresolved: the kernel cannot prevent information leakage through timing channels.
Of course, in this respect seL4 is no worse than other general-purpose OSes, but in seL4’s case it’s the last remaining security problem, while others have bigger issues to deal with. In fact, given our experience with trying to stop leakage on commercial hardware, I strongly suspect that all “high-assurance” separation kernels (which are based on strict space and time partitioning, SATP) leak as well.

Time protection partitions a system, including the kernel.
Our recent work on time protection indicates that we can solve this problem in seL4, by temporally or spatially partitioning all shared hardware resources, we partition even the kernel. This assumes that the hardware manufacturers get their act together and provide mechanisms for resetting all time-shared resources (and I’m working on the RISC-V Foundation to ensure that RISC-V does).
However, so far our time-protection is a set of primitive mechanisms. They require a proper integration with the seL4 model, which we are working on right now. This will then create a new verification challenge, which we think is solvable.
Design for Real-World Use
Suitability for real-world use really mans two things: generality and performance.
Generality
For a microkernel, this means keeping it as much as possible policy-free, and instead providing primitive mechanisms that are general enough to support the construction of virtually arbitrary systems on top.
Core to this is seL4’s capability-based access-control model (strongly influenced by KeyKOS and EROS), with its support for efficient delegation. And it required solving the resource-management problems that had plagued L4 (and other) microkernels in the past. Details of this model have evolved (as discussed above), the principles and “look-and-feel” have remained.
Whether we hit the right design point is still undecided. For years we were busy supporting various security- and safety-critical deployments (and evolving the system to improve this support) that we have not focussed very much on truly general systems, including flexible multi-server architectures. This is on-going work, which recently has accelerated.
Performance
When we started the seL4 project, my message to the team was unambiguous: “I will not consider this project a success if we lose more than 10% in IPC performance against the fastest kernel we’ve built to date.”
At the time of the first publication on seL4 (SOSP, Nov’09), the verified kernel was right at that 10% limit (the unverified version was faster and almost on par with our previous ARM kernel). Further work on verification-friendly micro-optimisation of the IPC fastpath resulted in the verified seL4 outperforming all our previous kernels. And that means verified seL4 outperforms any microkernel. In almost all cases that’s by about a factor of 10 in IPC latency. The closest in performance is the Fiasco.OC (L4Re) microkernel, which is only about a factor two slower than seL4. As I said earlier: Security is no excuse for poor performance!
Our uncompromising performance focus means that we cannot take shortcuts others regularly take, and is, for example, the reason our (high-performance) multicore version is not yet verified. But it’ll happen!
Real-world deployments
That our design-for-real-use works is shown by the fact that seL4 uptake is accelerating. One might think that ten years are a long time for this, but keep in mind that for the first half of this period, seL4 was locked up in IP arrangements that make it essential useless for anything but an internal research and teaching vehicle. Furthermore, deploying seL4 for enforcing security or safety means that (unless you are developing a system from scratch) you have re-architect your system thoroughly. This is not something people enter into lightly, and it also takes time.

Boeing ULB flying on seL4.
The DARPA HACMS program was a great success in this regard. Not only did HACMS show successful use of seL4 in real-world systems: Boeing’s Unmanned Little Bird (ULB) autonomous helicopter and US Army autonomous trucks.
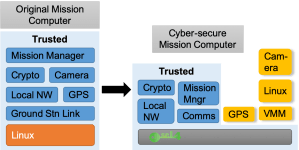
Cyber-retrofit of ULB.
More importantly, it demonstrated the feasibility of using seL4 to retrofit security into an existing real-world system,
a process dubbed incremental cyber-retrofit by then DARPA I2O Director John Launchbury. This is an approach we (and others) are presently taking to harden a number of real-world systems.
It is in the nature of open source that we only know about a fraction of the projects building on seL4, and it is not unusual that I find out about one of them by accident. And some projects we are involved in are commercial-in-confidence. But there are some I can talk about.
- A USB-based secure communication device, which uses military-strength encryption to communicate via Bluetooth or Wifi, has been evaluated and approved for defence use. To my knowledge this is the first time that software (i.e. seL4) enforced isolation was considered equivalent to air gapping by a certification authority. It is already in use in several defence forces.
CDDC displaying windows of different classifications.
- The Cross-Domain Desktop Compositor (CDDC) is a device that allows securely connecting a single keyboard, mouse and display to multiple networks of different security classifications or domains. Technically it is a drop-in replacement for a KVM switch, but more powerful, as it supports the concurrent rendering of windows from multiple domains on the same screen. Hardware ensures that each window is decorated according to its classification, and there is a reserved region on the screen that indicates where inputs go to. If so configured, the system allows the operator to cut-and-paste between windows. Previous designs (not using seL4) left certification authorities unconvinced of their security. The CDDC is about to enter a productisation phase.
- HENSOLDT Cyber is developing a secure hardware-software system, based on their own secure RISC-V chip, and an seL4-based secure operating system. [Disclosure: I’m chief scientist (software) of HENSOLDT Cyber.] It targets critical systems in defence, avionics, industrial automation and automotive.
- A US-based autonomous driving startup is using seL4 to protect the safety of its systems.
- There are various seL4-based TrustZone TEEs in development. And the Keystone TEE for RISC-V is based on seL4.
- Third parties are running seL4 training courses.
- A US DoD-funded organisation has run an seL4 Summit last year and is running another one this year.
This is a selection, there is much more going on, and deployments are definitely accelerating.
The Future
Above I listed number of current engineering projects, including full, verified RISC-V support, and verifying and mainlining the MCS model. On top of that we’re looking for funding to verify the 64-bit Arm v8 port. The differences in the privileged ISA between Arm v7 and v8 are big enough to make this essentially an architecture port, comparable to RISC-V. But the RISC-V verification project resulted in improved abstractions in the proof architecture which should reduce cost.
Then there is the verification of the multicore kernel, which I said is on-going, although slowly. I’m hopeful we’ll be able to accelerate this significantly with external funding. This has significant research challenges to address, besides the proof engineering.
And the there is time protection, where we have developed the core mechanism, but not yet a proper security model integrated into the seL4 API, this is on-going research, as is the verification of the mechanisms.
In this context I’d like to come up with a better (verifiable) confidentiality notion than the sledge-hammer information flow, which is super-restrictive and only applicable to a narrow set of realistic scenarios. We want something that is much more practicable.
Besides that we are working on strongly growing the seL4 community, especially fostering the seL4 open-source community. We have taken a number of steps there, including an RFC process. Much more is in the pipeline, and I hope we’ll be able to make an announcement in the near future.
Stay tuned!
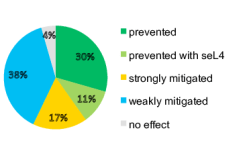
Many of us operating systems researchers, going back at least to the US DoD’s famous 1983 Orange Book, have been saying that a secure/safe system needs to keep its trusted computing base (TCB) as small as possible. For system of significant complexity, this argues for a design where components are protected in their own address spaces by an underlying operating system (OS). This OS is inherently part of the TCB, and such should itself be kept as small as possible, i.e. based on a microkernel, which comprises only some 10,000 lines of code. Which is why I have spent about a quarter century on improving microkernels, culminating in seL4, and getting them into real-world use.
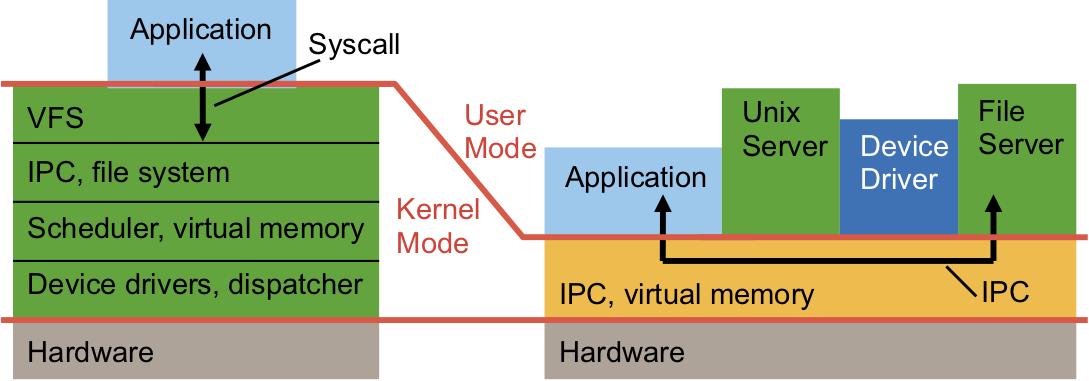
Monolithic vs microkernel-based OS structure.
It is intuitive (although not universally accepted) that a microkernel-based system has security and safety advantages over a large, monolithic OS, such as Linux, Windows or macOS, with their million-lines-of-code kernels. Surprisingly, we lacked quantitative evidence backing this intuition, beyond extrapolating defect density statistics to the huge TCBs of monolithic OSes.
Finally, the evidence is here, and it is compelling
Together with two undergraduate students, I performed an analysis of Linux vulnerabilities listed as critical in the Common Vulnerabilities and Exposures (CVE) database. A vulnerability is tagged critical if it I easy to exploit and leads to full system compromise, including full access to sensitive data and full control over the system.
For each of those documented vulnerabilities we analysed how it would be affected if the attack were performed against a feature-compatible, componentised OS, based on the seL4 microkernel, that minimised the TCB. In other words, an application running on this OS should only be dependent on a minimum of services required to do its job, and no others.
We assume that the application requires network services (and thus depend on the network stack and a NIC driver), persistent storage (file system and a storage device driver) and console I/O. Any OS services not needed by the app should not be able to impact its confidentiality (C), integrity (I) and availability (A). For example, an attack on a USB device should not impact our app. Such a minimal TCB architecture is exactly what microkernels are designed to support.
The facts
The complete results are in a peer-reviewed paper, I’m summarising them here. We find that of all of the 115 critical Linux CVEs, we could analyse 112, the remaining 3 did not have enough information to understand how they could be mitigated. Of those 112:
- 33 (29%) were eliminated simply by implementing the OS as a componentised system on top of a microkernel! These are attacks against functionality Linux implements in the kernel, while a microkernel-based OS implements them as separate processes. Examples are file systems and device drivers. If a Linux USB device driver is compromised, the attacker gains control over the whole system, because the driver runs with kernel privileges. In a well-designed microkernel-based system, only the driver process is compromised, but since our application does not require USB, it remains completely unaffected.
- A further 12 exploits (11%) are eliminated if the underlying microkernel is formally verified (proved correct), as we did with seL4. These are exploits against functionality, such as page-table management, that must be in the kernel, even if it’s a microkernel. A microkernel could be affected by such an attack, but in a verified kernel, such as seL4, the flaws which these attacks target are ruled out by the mathematical proofs.
Taken together, we see that 45 (40%) of the exploits would be completely eliminated by an OS designed based on seL4! - Another 19 (17%) of exploits are strongly mitigated, i.e. reduced to a relatively harmless level, only affecting the availability of the system, i.e. the ability of the application to make progress. These are attacks where a required component, such as NIC driver or network stack, is compromised, and as a result compromising the whole Linux system, while on the microkernel it might lead to the network service crashing (and becoming unavailable) without being able to compromise any data. So, in total, 57% of attacks are either completely eliminated or reduced to low severity!
- 43 exploits (38%) are weakly mitigated with a microkernel design, still posing a serious security threat but no longer qualifying as “critical”. Most of these were attacks that manage to control the GPU, implying the ability to manipulate the frame buffer. This could be used to trick the human user into entering sensitive information that could be captured by the attacker.
Only 5 compromises (4%) were not affected by OS structure. These are attacks that can compromise the system even before the OS assumes control, eg. by compromising the boot loader or re-flashing the firmware, even seL4 cannot defend against attacks that happen before it is running.
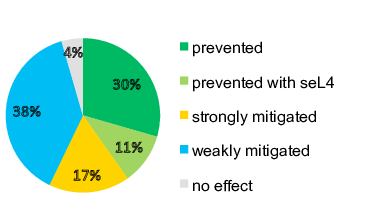
Effect of (verified) microkernel-based design on critical Linux exploits.
What can we learn from this?
So you might ask, if verification prevents compromise (as in seL4), why don’t we verify all operating systems, in particular Linux? The answer is that this is not feasible. The original verification of seL4 cost about 12 person years, with many further person years invested since. While this tiny compared to the tens of billions of dollars worth of developer time that were invested in Linux, it is about a factor 2–3 more than it would cost to develop a similar system using traditional quality assurance (as done for Linux). Furthermore, verification effort grows quadratically with the size of the code base. Verifying Linux is completely out of the question.
The conclusion seems inevitable: The monolithic OS design model, used by Linux, Windows, macOS, is fundamentally and irreparably broken from the security standpoint. Security is only achievable with a (verified) microkernel design. Furthermore, using systems like Linux in security- or safety-critical applications is at best grossly negligent and must be considered professional malpractice. It must stop.
