
The disclosure of the Meltdown and Spectre computer vulnerabilities on January 2, 2018 was in many ways unprecedented. It shocked – and scared – even the experts.
The vulnerabilities bypass traditional security measures in the computer and affect billions of devices, from mobile phones to massive cloud servers.
We have, unfortunately, grown used to attacks on computer systems that exploit the inevitable flaws resulting from vast conceptual complexity. Our computer systems are the most complex artefacts humans have ever built, and the growth of complexity has far outstripped our ability to manage it.
A new kind of vulnerability
Meltdown and Spectre are qualitatively different from previous computer vulnerabilities. Not only are they effective across a wide class of computer hardware and operating systems from competing vendors. And not only were the vulnerabilities hiding in plain sight for more than a decade. The really shocking realisation is that Meltdown and Spectre do not exploit flaws in the computer hardware or software.
As Intel stated in its press release, these attacks:
…gather sensitive data from computing devices that are operating as designed.
The ingenuity of the attacks lies in combining seemingly unrelated design features that were thought to be well understood – stuff we teach undergraduate computer science students. The vulnerability is not in any of the individual features, but in the complex interaction between them.
It turns out that computer systems are insecure not because of mistakes made in the implementation, but because of ill-conceived design.
As a community of computer systems experts, we have to ask ourselves how such a debacle is possible, and how a recurrence can be prevented.
We have known for a while that the established “wait for something to happen and then try to fix it” approach – better known as “patch and pray” – does not work even for more common implementation flaws, as witnessed by the proliferation of exploits. It works even less well for such insecure-by-design situations.
Automated evaluation of designs
The fundamental problem is that humans are unable to fully understand the conceptual complexity of modern computer systems and how its seemingly unrelated features might interact. There is no hope that this will change.
But solving complex problems is what machines are increasingly good at. So, the only real solution can be the automated evaluation of designs, with the aim of mathematically proving that under all circumstances a design will behave in a way that is considered secure – in particular by not leaking secret data.
In other words, a design must be considered insecure unless there is a rigorous mathematical proof to the contrary.
This is not an easy ask by any definition, and much more work across many areas of computer science and engineering is needed to make it a reality. But we need to start somewhere, and we need to start now.
We will reap benefits of embarking on such a program long before we achieve the goal of rigorous end-to-end proof. Significant improvements will be achieved through partial results, both in the form of proving weaker properties, and by establishing desired properties in a less rigorous fashion.
For example, an incomplete evaluation may be more feasible than a complete one, and produce a probabilistic result, such as a greatly reduced likelihood of exploits.
Rewriting the hardware-software contract
A necessary, and overdue, first step is a new and improved hardware-software contract.
Computer systems are a combination of hardware and software. The people and companies that develop hardware are largely separate from those developing the software. Given the vastly different skills and experience required, this is inevitable.
To make development practical, both sides work to an interface, called the instruction-set architecture (ISA), which presents the contract between hardware and software functionality.
The problem, clearly exhibited by the Meltdown and Spectre attacks, is that the ISA is under-specified for security, or safety for that matter. It simply does not provide ways to isolate the speed of progress of a computation from other system activities.
The ISA is a functional specification, meaning it defines how the visible state of the machine will (eventually) change if an operation is triggered. It intentionally abstracts away anything to do with time. In particular, it hides how long operations take and how this time depends on the internal state of the machine. The problem is that this internal state depends on potentially confidential data processed by previous operations.
This means that by observing the exact timing of particular sequences of operations, it is possible to infer data that is supposed to be kept secret. This is exactly what happened with Meltdown and Spectre.
The abstraction is there for a good reason: It allows hardware designers to change things “under the hood”, usually in order to improve performance. Consequently, there will be resistance from hardware manufacturers to a tighter contract. But we believe that the refined specifications can be kept abstract enough to retain manufacturers’ ability to innovate, and to avoid exposing confidential IP.
![]() The recent debacle has shown that the ISA is too abstract, making it impossible to tell whether a system is secure or if it will leak secrets. This must change, urgently.
The recent debacle has shown that the ISA is too abstract, making it impossible to tell whether a system is secure or if it will leak secrets. This must change, urgently.
Co-authored with Yuval Yarom, Researcher, CSIRO’s Data61; Senior Lecturer, University of Adelaide
This article was originally published on The Conversation. Read the original article.
People increasingly depend on cloud services for business as well as private use. This raises concerns about the security of clouds, which is usually discussed in the context of trustworthiness of the cloud provider and security vulnerability of cloud infrastructure, especially the hypervisors and cryptographic libraries they employ.
We have just demonstrated that the risks go further. Specifically, we have shown that it is possible to steal encryption keys held inside a virtual machine (that may be hosting a cloud-based service) from a different virtual machine, without exploiting any specific weakness in the hypervisor, in fact, we demonstrated the attack on multiple hypervisors (Xen as well as VMware ESXi).
Cache-based Timing Channels
The performance of modern computing platforms is critically dependent on caches, which buffer recently used memory contents to make repeat accesses faster (exploiting spatial and temporal locality of programs). Caches are functionally transparent, i.e. they don’t affect the outcome of an operation (assuming certain hardware or software safeguards), only its timing. But the exact timing of a computation can reveal information about its algorithms or even the data on which it is operating – caches can create timing side channels.
In principle, this is well understood, and cloud providers routinely take steps to prevent timing channels, by not sharing processor cores between virtual machines belonging to different clients.
Preventing L1-based cache channels
Why does this help? Any exploitation of a cache-based channel inherently depends on shared access (between the attacker and the victim) of this hardware resource. An attacker has no direct access to the victim’s data in the cache, instead cache attacks are based on the attacker’s and victim’s data competing for space in the cache. Basically, the attacker puts (parts of) the cache into a defined state, and then observes how this changes through the competition for cache space by the victim.
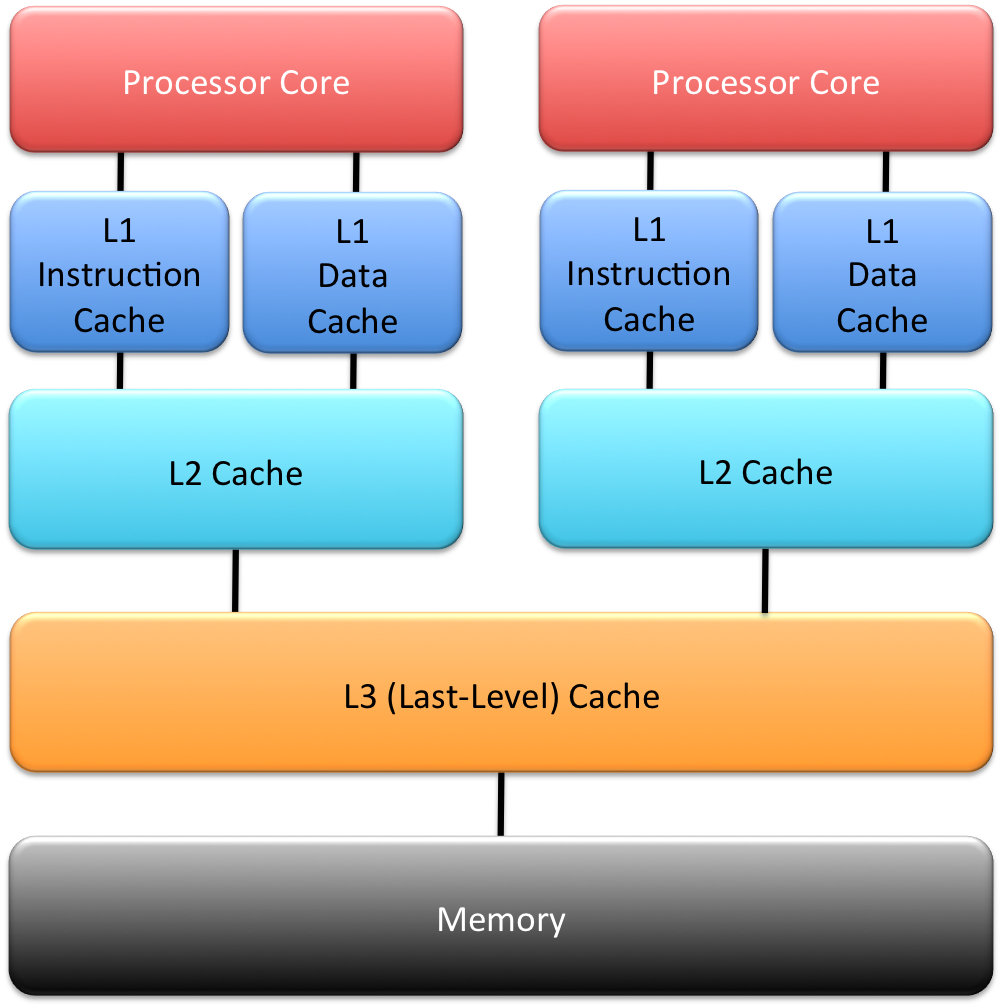
Memory architecture in a modern x86 processor.
Modern processors have a hierarchy of caches, as shown in the diagram to the right. The top-level “L1” caches (there is usually a separate L1 for data and instructions) are fastest to access by programs executing on the processor core. If a core is shared between concurrently executing virtual machines (VMs), as is done through a hardware feature called hyperthreading, the timing channel through the cache is trivial to exploit.
So, hypervisor vendors recommend disabling hyperthreading, and we can assume that any responsible cloud provider follows that advice. Hyperthreading can provide a performance boost for certain classes of applications, but typical cloud-based services probably don’t benefit much, so the cost of disabling hyperthreading tends to be low.
In principle, it is possible to exploit the L1 timing channel without hyperthreading, if the core is multiplexed (time-sliced) between different VMs. However, this is very difficult in practice, as the L1 caches are small, and normally none of the attacker’s data survives long enough in the cache to allow the attacker to learn much about the victim’s operation. Small caches imply a small signal. (Attacks against time-sliced L1 caches generally requiring the attacker to force high context-switching rates, eg by forcing high interrupt rates, something the hypervisor/operator will consider abnormal behaviour and will try their best to prevent.)
In somewhat weaker form, what I have said about L1-based attacks also applies to other caches further down in the memory hierarchy, as long as they are private to a core. On contemporary x86 processors, this includes the L2 cache. L2 attacks tend to be harder than L1 attacks for a number of reasons (despite the larger size of the L2, compared to the L1), and the same defences work.
Attacking through the last-level cache (L3)
The situation is different for the last-level cache (nowadays the L3), which, on contemporary x86 processors, is shared between multiple cores (either all cores on the processor chip, or a subset, called a cluster).
What is different is that, on the one hand, the cache is further away from the core, meaning much longer access times, which increases the difficulty of exploiting the timing channel. (Technically speaking, the longer access time reduces the sampling rate of the signal the attacker is trying to measure.) On the other hand, the fact that multiple cores access the same L3 concurrently provides an efficiency boost to the exploit (by increasing the rate at which the signal can be sampled), similar to the case of the L1 cache with hyperthreading enabled.
Still, L3-based attacks are difficult to perform, to the point that to date people generally don’t worry about them. There have been attacks demonstrated in the past, but they either depended on weaknesses (aka bugs) in a specific hypervisor (especially its scheduler) or on unrealistic configurations (such as sharing memory between VMs), which obviously break inter-VM isolation – a security-conscious cloud provider (or even a provider concerned about accounting for resources accurately) isn’t going to allow those.
It can be done!
However, these difficulties can be overcome. As we just demonstrated in a paper that will be presented at next month’s IEEE Security and Privacy (“Oakland”) conference, one of the top security venues, the L3 timing channel can be exploited without unrealistic assumptions on the host installation. Specifically:
- We demonstrated that we can steal encryption keys from a server running concurrently, in a separate VM, on the processor.
- Stealing a key can be done in less than a minute in one of our attacks!
- The attack does not require attacker and victim to share a core, they run on separate cores of the same processor.
- The attack does not exploit specific hypervisor weaknesses, in fact we demonstrated it on two very different hypervisors (Xen as well as VMware ESXi).
- The attack does not require attacker and victim to share memory, even read-only (in contrast to earlier attacks).
- We successfully attack multiple versions of encryption (which use different algorithms).
What does this mean in practice?
The implications are somewhat scary. The security of everything in clouds depends on encryption. If you steal encryption keys, you can masquerade as a service, you can steal personal or commercial secrets, people’s identity, the lot.
Our attack targeted two specific implementations of a crypto algorithm in the widely used GnuPG crypto suite, it exploits some subtle data-dependencies in those algorithms, which affect cache usage, and thus can be analysed by a sophisticated attacker to determine the (secret!) encryption keys. Ethics required that we informed the maintainers to allow them to fix the problem (we provided workarounds) before it became public. The maintainers updated their code, so an installation running up-to-date software will not be susceptible to our specific attack.
However, the problem goes deeper. The fact that we could successfully attack two different implementation of encryption means that there are likely ways to attack other encryption implementations. The reason is that it is practically very difficult to implement those algorithms without any exploitable timing variations. So, one has to assume that there are other possible attacks out there, and if that’s the case, it is virtually guaranteed that someone will find them. Eventually such a “someone” will be someone nasty, rather than ethical researchers.
Why do these things happen?
Fundamentally, we are facing a combination of two facts:
- Modern hardware contains a lot of shared resources (and the trend is increasing).
- Mainstream operating systems and hypervisors, no matter what they are called, are notoriously poor at managing, and especially isolating, resources.
Note that we did not exploit anything in the hypervisor most people would consider a bug (although I do!), they are simply bad at isolating mutually-distrusting partitions (as VMs in a cloud are). And this lack of isolation runs very deep, to the degree that it is unlikely to be fixable at realistic cost. In other words, such attacks will continue to happen.
To put it bluntly: From the security point of view, all main-stream IT platforms are broken beyond repair.
What can be done about it?
Defending legacy systems
The obvious way to prevent such an attack is never to share any resources. In the cloud scenario, this would mean not running multiple VMs on the same processor (not even on different cores of that processor).
That’s easier said than done, as it is fundamentally at odds with the whole cloud business model.
Clouds make economic sense because they lead to high resource utilisation: the capital-intensive computing infrastructure is kept busy by serving many different customers concurrently, averaging out the load imposed by individual clients. Without high utilisation, the cloud model is dead.
And that’s the exact reason why cloud providers have to share processors between VMs belonging to different customers. Modern high-end processors, as they are deployed in clouds, have dozens of cores, and the number is increasing, we’ll see 100-core processors becoming mainstream within a few years. However, most client VMs can only use a small number of cores (frequently only a single one). Hence, if as a cloud provider you don’t share the processor between VMs, you’ll leave most cores idle, your utilisation goes down to a few percent, and you’ll be broke faster than you can say “last-level-cache timing-side-channel attack”.
So, that’s a no-go. How about making the infrastructure safe?
Good luck with that! As I argued above, systems out there are pretty broken in fundamental ways. I wouldn’t hold my breath.
Taking a principled approach to security
The alternative is to build systems for security from the ground up. That’s hard, but not impossible. In fact, our seL4 microkernel is exactly that: a system designed and implemented for security from the ground up – to the point of achieving provable security. seL4 can form the base of secure operating systems, and it can be used as secure hypervisor. Some investment is needed to make it suitable as a cloud platform (mostly to provide the necessary management infrastructure), but you can’t expect to get everything for free (although seL4 itself is free!)
While seL4 has already a strong isolation story, so far this extends to functional behaviour, not yet timing. But we’re working on exactly that, and should have a first solution this year.
So, why should you believe me that it is possible to add such features to seL4, but not to mainstream hypervisors? The answer is simple: seL4 is designed from ground up for high security, and none of the mainstream systems is. And second, seL4 is tiny, about 10,000 lines of code. In contrast, main-stream OSes and hypervisors consist of millions of lines of code. This not only means they are literally full of bugs, thousands and thousands of them, but also that it is practically impossible to change them as fundamentally as would be required to making them secure in any serious sense.
In security, “small is beautiful” is a truism. And another one is that retrofitting security into a system not designed for it from the beginning doesn’t work.
Update June’16
Researchers from Wochester Polytechnic have in the meantime demonstrated our attack on a real Amazon AC2 cloud. This shows beyond doubt that the threat is real. Which, of course, doesn’t stop could providers from sticking their heads in the sand.
The ARC released the composition of the ERA’15 Research Evaluation Committees (RECs) a few days ago. The one relevant to us is the Mathematics, Information and Computing Sciences (MIC) REC. So I was a bit surprised when I looked at it and recognised almost no names.
For those living outside Australia, outside academia, or have their head firmly burrowed in the sand, ERA is the Excellence in Research for Australia exercise the Australian Research Council (ARC, Oz equivalent of the NSF) has been running since 2010. It aims to evaluate the quality of research done at Australian universities. I was involved in the previous two rounds, 2010 as a member of the MIC panel, and 2012 as a peer reviewer.
The ERA exercise is considered extremely important, universities take it very seriously, and a lot of time and effort goes into it. The outcomes are very closely watched, universities use it to identify their strengths and weaknesses, and everyone expects that government funding for universities will increasingly be tied to ERA rankings.
The panel is really important, as it makes the assessment decisions. Assessment is done for “units of evaluation” – the cartesian product of universities and 4-digit field of research (FOR) codes. The 4-digit FORs relevant to computer science and information systems are the various sub-codes of the 2-digit (high-level) code 08 – Information and Computing Sciences.
For most other science and engineering disciplines, assessment is relatively straightforward: you look at journal citation data, which is a pretty clear indication of research impact, which in turn is a not unreasonable proxy for research quality. In CS, where some 80% of publications are in conferences, this doesn’t work (as I’ve clearly experienced in the ERA’10 round): the official citation providers don’t understand CS, they don’t (or only very randomly) index conferences, they don’t count citations of journal papers by conference papers, and the resulting impact factors are useless. As a result, the ARC moved to peer-review for CS in 2012 (as was used by Pure Maths and a few other disciplines in 2010 already).
Yes, the obvious (to any CS person) answer is to use Google Scholar. But for some reason or other, this doesn’t seem to work for the ARC.
Peer review works by institutions nominating 30% of their publications for peer review (the better ones, of course), and several peer reviewers are each reviewing a subset of those (I think the recommended subset is about 20%). The peer reviewer then writes a report, and the panel uses those to come up with a final assessment. (Panelists typically do a share of peer review themselves.)
Peer review is inevitably much more subjective than looking at impact data. You’d like to think that the people doing this are the leaders in the field, able to objectively assess the quality of the work of others. A mediocre researcher is likely to emphasise factors that would make themselves look good (although they are, of course, excluded from any discussion of their own university). Basically, I’d trust the judgment someone with an ordinary research track record much less than that of a star in the field.
So, how does the MIC panel fare? Half of it are mathematicians, and I’m going to ignore those, as I wouldn’t be qualified to say anything about their standing. But for CS folks, citation counts and h-factors as per google scholar, in the context of the number of years since their PhD, is a very good indication. So let’s look at the rest of the MIC panellists, i.e. the people from computer science, information systems or IT in general.
| Name | Institution | years of PhD | cites | h-index |
|---|---|---|---|---|
| Leon Sterling (Chair) | Swinburne | ~25 | 5,800 | 28 |
| Deborah Bunker | USyd | 15? | max cite =45 | |
| David Green | Monash | ~30 | 3,400 | 30 |
| Jane Hunter | UQ | 21 | 3,400 | 29 |
| Michael Papazoglou | Tilburg | 32 | 13,200 | 49 |
| Paul Roe | QUT | 24 | <1,000 | 17 |
| Markus Stumptner | UniSA | ~17 | 2,900 | 28 |
| Yun Yang | Swinburne | ~20 | 3,800 | 30 |
[Note that Prof Bunker has no public Scholar profile, but according to Scholar, her highest-cited paper has 45 citations. Prof’s Sterling’s public Scholar profile includes as the top-cited publication (3.3k cites) a book written by someone else, subtracting this leads to the 5.8k cites I put in the table. Note that his most cited publication is actually a textbook, if you subtract this the number of cites is 3.2k.]
Without looking at the data, one notices that only three of the group are from the research-intensive Group of Eight (Go8) universities, plus one from overseas. That in itself seems a bit surprising.
Looking at the citation data, one person is clearly in the “star” category: the international member Michael Papazoglou. None of the others strike me as overly impressive, a h-index of around 30 is good but not great, similar with citations around the 3000 mark. And in two cases I can really only wonder how they could possibly been selected. Can we really not come up with a more impressive field of Australian CS researchers?
Given the importance of ERA, I’m honestly worried. Those folks have the power to do a lot of damage to Australian CS research, by not properly distinguishing between high- and low-quality research.
But maybe I’m missing something. Let me know if you spot what I’ve missed.
What did I learn from this all?
Clearly, OK Labs was, first off, a huge missed opportunity. Missed by a combination of greed, arrogance and stupidity, aided by my initial naiveté and general lack of ability to effectively counter-steer.
That arrogance and greed is a bad way of dealing with customers and partners was always clear to me, although a few initial successes made this seem less obvious for a while. In the end it came back to haunt us.
Strategically it was a mistake looking for investment without a clear idea of what market to address and what product to build. We didn’t need the investment to survive, we had a steady stream of revenue that would have allowed us to grow organically for a while until we had a clearer idea what to grow into. Instead we went looking for investment with barely half-baked ideas, a more than fussy value proposition and a business plan that was a joke. As a result, we ended up with 2nd- or 3rd-tier investors and a board that was more of a problem than a solution. But, of course, Steve, being the get-rich-fast type, wanted a quick exit.
A fast and big success isn’t generally going to happen with the type of technology we had (a very few extreme examples to the contrary notwithstanding). Our kind of technology will eventually take over, but it will take a while. It isn’t like selling something that helps you improve your business, or provide extra functionality for your existing product, something that can be trialled with low risk.
Our low-level technology requires the adopter to completely re-design the critical guts of their own products. This not only takes time, it also bears a high risk. Customers embarking on that route cannot risk failure. Accordingly, they will take a lot of time to evaluate the technology, the risks and upsides associated with it, trial it on a few less critical products, etc. All this takes time, and It is unreasonable to get significant penetration of even a single customer in less than about 5 years.
So, it’s the wrong place for a get-rich-fast play. But understanding that takes more technical insight than Steve will ever have, and executing it requires more patience then he could possibly muster. And, at the time, I didn’t have enough understanding of business realities to see this.
What this also implies is that for a company such as OK Labs, it is essential that the person in control has a good understanding of technology (ours as well as the customers’). This is not the place for an MBA CEO (and Steve is a far cry from an MBA anyway). Business sense is importance (and I don’t claim I’ve got enough of it), but in the high-tech company, the technologist must be in control. This is probably the most important general lesson.
Personally I learnt that I should have trusted my instincts better. While not trained for the business environment, the sceptical-by-default approach that is the core to success in research (and which I am actively baking into my students) serves one well beyond direct technical issues. The challenge is, of course, that people not used to it can easily mistake it as negativity – particularly people who are not trained for or incapable of analysing a situation logically.
I’ve learnt that, when all a person says about stuff you understand well is clearly all bullshit, then there’s a high probability that everything else they say is all bullshit too. I should have assumed that, but I gave the benefit of the doubt for far too long.
As mentioned earlier, I also learnt that it was a big mistake to be a part-timer at the company. This could have worked (and could potentially be quite powerful) if the CEO was highly capable, and there was a high degree of mutual trust and respect and we were aligned on the goals. But I wasn’t in that situation, unfortunately, and my part-time status allowed me to be sidelined.
Finally, I always believed that ethics are important, in research as well as in business. The OK experience confirms that to me. Screwing staff, partners and customers may produce some short-term success, but will bite you in the end.
© 2014 by Gernot Heiser. All rights reserved.Permission granted for verbatim reproduction, provided the reproduction is of the complete, unmodified text, is not made for commercial gain, and this copyright note is included in full. Fair-use abstracting permitted.
